因为这段时间的安排是抽时间学习一波springboot架构,不仅是因为工作需要,而且也是为了学习新的架构知识,因为springcloud微服务就是基于springboot的,只有把springboot摸透了,才好去学习更加强的东西。
今天把原定计划的Redis给撸了一遍,整合springboot,分布式全局共享session,Redis数据结构等等,做了几个小exp(也就是CRUD的操作罢了哈哈),剩下的时间去摸了下spring-data-jpa,不摸不要紧,tm的浪费了我半天的时间,不过也算是小有收获吧,不然岂不是亏死,接下来就把这个持久层框架的血泪踩坑经历给总结出来。
spring-data-jpa
其实JPA本身并不是一种框架,是一种规范,其全称是Java Persistence API,是是Sun官方提出的Java持久化规范,而他的出现主要是为了简化现有的持久化开发工作和整合ORM技术,并且其是在充分吸收了现有Hibernate,TopLink,JDO等ORM框架的基础上发展而来的,具有易于使用,伸缩性强等优点。
而官网对spring data jpa是这么介绍的:Spring Data JPA是Spring Data系列的一部分,可以轻松实现基于JPA的存储库。该模块处理对基于JPA的数据访问层的增强的支持。这使得使用数据访问技术构建Spring供电的应用程序变得更加容易。
其本质就是像mybatis,hibernate那样与数据库进行交互的ORM技术,其原理就是整合了Hibernate的封装库,因为刚开始肯定要在网上找代码来看看具体逻辑到底是什么样的,这里我是以翟永超的springboot教程里面的整合spring-data-jpa这节来学习的,想学的朋友也可以直接到他的blog上去找项目来看,所有的项目的都在github上可以下载到。
教程链接:http://blog.didispace.com/springbootdata2/
首先我是先看完代码后想自己模仿着完成一个小案例,将数据存入数据库内,再把它取出来(这tm是最简单的操作了把),没想到这个框架极恶心,总之我是困在了NullPointerException上了。。。
我先从他的开源项目上去分析一下他的代码。
首先他是将依赖包导入到POM中,看看导入代码:
<!-- Mysql -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.21</version>
</dependency>
<!-- spring-data-jpa -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
以MySQL数据库为例,先引入MySQL连接的依赖包,然后直接在application.properties中配置数据源的参数信息。
spring.datasource.url=jdbc:mysql://localhost:3306/test
spring.datasource.username=dbuser
spring.datasource.password=dbpass
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.jpa.properties.hibernate.hbm2ddl.auto=create
spring.jpa.properties.hibernate.hbm2ddl.auto是hibernate的配置属性,其主要作用是:自动创建、更新、验证数据库表结构。该参数的几种配置如下:
-create:每次加载hibernate时都会删除上一次的生成的表,然后根据你的model类再重新来生成新表,哪怕两次没有任何改变也要这样执行,这就是导致数据库表数据丢失的一个重要原因。表示启动的时候先drop,再create.
-create-drop:每次加载hibernate时根据model类生成表,但是sessionFactory一关闭,表就自动删除。也表示创建,只不过再系统关闭前执行一下drop.
-update:最常用的属性,第一次加载hibernate时根据model类会自动建立起表的结构(前提是先建立好数据库),以后加载hibernate时根据model类自动更新表结构,即使表结构改变了但表中的行仍然存在不会删除以前的行。要注意的是当部署到服务器后,表结构是不会被马上建立起来的,是要等应用第一次运行起来后才会。这个操作启动的时候会去检查schema是否一致,如果不一致会做scheme更新.最常用的就是这个了。。。
-validate:每次加载hibernate时,验证创建数据库表结构,只会和数据库中的表进行比较,不会创建新表,但是会插入新值。 启动时验证现有schema与你配置的hibernate是否一致,如果不一致就抛出异常,并不做更新。
我在后面的时候要测试时发现数据在程序中已经执行成功存入数据库了,可是在查看数据库的时候却没有发现生成响应的表,我后来发现我用了create-drop这个参数,因为我用testNG测的,测试模块一结束,sessionFactory就关闭了,所以生成的表也就自动删除了,所以我这里改成create,这样数据导入的时候,我们可以在数据库里面看到相应的表生成。
如果是在本机上进行调试,则url可以写成jdbc:mysql:///test也可以。。。
注意test是你的数据库名字,如果没有这个数据库就会报mysql错误,我刚开始也是以为会自动建库,小失误。
事先要把这个test库给建立起来,mysql如何建库这个不说了吧。。
配置好后,这里先来看看一些jpa的基本注解,我们会用这些注解来写案例:
@Entity :修饰实体类,指明该类将映射到指定的数据表,例如:Customer 类默认的数据表名为 customer
@Table :当实体类与映射的数据库表名不同名时需要使用 @Table 注解,该注解与 @Entity 注解并列使用,使用其 name 属性指明数据库的表名
@Table(name = “JPA_CUSTOMER表名”)@Id :标识该属性为主键,一般标注在该属性的 getter 方法上
@GeneratedValue :标注主键的生成策略,通过其 strategy 属性。通常与 @Id 注解一起使用。默认情况下 JPA 会自动选择一个最适合底层数据库的主键生成策略,MyS
默认为 AUTO,常用策略有:
–IDENTITY:采用数据库 ID自增长的方式来自增主键字段,Oracle 不支持这种方式;
–AUTO: JPA自动选择合适的策略,是默认选项;
–SEQUENCE:通过序列产生主键,通过 @SequenceGenerator 注解指定序列名,MySql 不支持这种方式
–TABLE:通过表产生主键,框架借由表模拟序列产生主键,使用该策略可以使应用更易于数据库移植
例:@GenerateValue(strategy=GenerationType.AUTO),写在id属性的上面,主键策略。
@Basic :用于没有任何标注的 getXxx() 方法,默认即为 @Basic,所以若一个 getter 方法无任何注解,可以使用 @Basic 注解,也可以不使用
@Column :当实体的属性与其映射的数据表的列不同名时使用,一般用于 getter 方法上。其 name 属性用来指明此属性在数据表中对应的列名;unique 属性指明是否为唯一约束;nullable 属性用来指明是否可以为空,false 为不能为空;length 属性指明此列的长度。
通常写在普通属性上:@Column(name=”LAST_NAME”,length=50,nullable=false)
nullable表示不允许为空。@Transient :标注此注解后在创建数据表的时候将会忽略该属性 Customer 类并没有 info 这个属性,所以数据库中也不应该有 info 这个字段
@Temporal :向数据库映射日期(Date)属性时用来调整映射的精度。Date 类型的数据有 DATE, TIME, 和 TIMESTAMP 三种精度(即单纯的日期,时间,或者两者兼备).
Birth 属性应该使用 DATE 类型(生日只具体到日即可,如:2015-10-22),而 CreateTime 应该使用 TIMESTAMP 类型(创建时间应该具体到秒,如:2017-10-11 22:39:13)
注解讲完后,可以开始进入项目了,项目中我们需要建立实体类。(以User为例)
实体类需要建立@Entity注解以标记为实体类,映射到数据库中,自动生成的表名与这个实体类的类名一致
主键id需要加@Id和@GeneratedValue(strategy = GenerationType.IDENTITY)
原项目中的@GeneratedValue注解没有加后面的参数,所以为了保证不出错,加上参数,
JPA为开发人员提供了四种主键生成策略,被定义在枚举类GenerationType中,包含(TABLE , SEQUENCE , IDENTITY , AUTO).
先介绍下这四种策略:
(1)GenerationType.TABLE
使用一个特定的数据库表格来保存主键,持久化引擎通过关系数据库的一张特定的表格来生成主键。
策略的优点:不依赖于外部环境和数据库的具体实现,在不同数据库间可以很容易的进行移植。
缺点:不能充分利用数据库的特性,一般不会优先使用。
(2)GenerationType.SEQUENCE
在某些数据库中,不支持主键自增长,比如Oracle,其提供了一种叫做”系列(sequence)”的机制生成主键。
该策略只要部分数据库(Oracle/PostgreSQL/DB2)支持序列对象,所以该策略一般不应用与其他数据库。
(3)GenerationType.IDENTITY
此种主键生成策略就是通常所说的主键自增长,数据库在插入数据时,会自动给主键赋值,比如Mysql可以在创建表时声明”auto_increment”来指定主键自增长。大部分数据库都提供了该支持。我使用了这种。。。
(4)GenerationType.AUTO
把主键生成策略交给持久化引擎,持久化引擎会根据数据库在以上三种主键生成策略中选择其中一种。因为这种策略比较常用,所以JPA默认的生成策略就是AUTO.这种方式如果数据库中不存在这张表的时候,用它来指定自增方式没有问题,但是如果数据库中已经存在这张表并设计了自动方式,那么插入数据的时候就会报错。
@Entity
public class User {
@Id
@GeneratedValue
private Long id;
@Column(nullable = false)
private String name;
@Column(nullable = false)
private Integer age;
public User(){}
public User(String name, Integer age) {
this.name = name;
this.age = age;
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
}
接下来是DAO:
spring data jpa让我们解脱了DAO层的操作,基本上所有CRUD都可以依赖于它来实现,在里面就集成了一种方法就是自动编写SQL,但是如果我们要复杂SQL的时候,jpa也给我们提供了@Query用于我们自己编写sql语句,当然这是jpa特有的编写规范。
它们分别实现了按name查询User实体和按name和age查询User实体,可以看到我们这里没有任何类SQL语句就完成了两个条件查询方法。这就是Spring-data-jpa的一大特性:通过解析方法名创建查询。
除了通过解析方法名来创建查询外,它也提供通过使用@Query 注解来创建查询,您只需要编写JPQL语句,并通过类似“:name”来映射@Param指定的参数,就像例子中的第三个findUser函数一样。
public interface UserRepository extends JpaRepository<User, Long> {
User findByName(String name);
User findByNameAndAge(String name, Integer age);
//:name是来映射@Param指定的参数,根据传递的参数来作为where查询的条件
//方法的参数个数必须和@Query里面需要的参数个数一致
//默认配置下, 使用了@Query注解后就不会再使用方法名解析的方式了
//这是命名化参数的形式,就是条件具体的指向参数,也可以用问号?索引方式来表达参数
@Query("from User u where u.name=:name")
User findUser1(@Param("name") String name);
//根据name和age的条件来查找数据,并返回User实例
@Query(value="select * from User u where u.name=?1 and u.age=?2",nativeQuery=true)
User findUser2(@Param("name")String name,@Param("age")Integer age);
}
JPQL主要用于JPA查询数据,和SQL语句的语法大同小异;
JPQL语言,即 Java Persistence Query Language 的简称。JPQL 是一种和 SQL 非常类似的中间性和对象化查询语言,它最终会被编译成针对不同底层数据库的 SQL 查询,从而屏蔽不同数据库的差异。 JPQL语言的语句可以是 select 语句、update 语句或delete语句,它们都通过 Query 接口封装执行。
Query注解自定义SQL查询
1.我们可以直接使用@Query来使用这个类的方法。
默认配置下, 使用了@Query注解后就不会再使用方法名解析的方式了…注意
@Query有几大属性,分别是:
方法的参数个数必须和@Query里面需要的参数个数一致
value里面的参数也可以用SPEL表达式来写,也就是#{…}语句,用于更灵活的配置参数,不用把sql语句写死。
-String value() default “”;//默认是空,value=sql语句,
比如@Query(“from User u where u.name=:name”)就可以写成
@Query(value=”from User u where u.name=:name”)
-boolean nativeQuery() default false;//默认是false
代表原生sql,所谓本地查询,就是使用原生的sql语句(根据数据库的不同,在sql的语法或结构方面可能有所区别)进行查询数据库的操作。调用这个以后就可以针对不同的数据库做对应的sql语法了(就像oracle和mysql一样,虽然大体相同但是还是存在一些小地方的差别)
当不需要表中的全字段时,可自定义dto类来接受查询结果,这种方法要注意使用new + dto类全路径+ (别名.field1, 别名.field2, 别名.field3), 且dto类中必须有对应参数结构的构造函数!别忘记加上无参的构造函数!
@Query("select new com.user.domain.UserDto(a.userName, a.gender) from User a where userId = :userId")
UserDto findByUserId(@Param("userId") userId);
2.修改操作加上 @Modify注解
@Query(value="update User set userId = :userId")
@Modify
User findByUserId(@Param("userId") userId);
3.如果是like(模糊查询),后面的参数需要前面或者后面加“%”,比如下面都对:
@Query("select o from UserModel o where o.name like ?1%")
public List<UserModel> findByUuidOrAge(String name);
@Query("select o from UserModel o where o.name like %?1")
public List<UserModel> findByUuidOrAge(String name);
@Query("select o from UserModel o where o.name like %?1%")
public List<UserModel> findByUuidOrAge(String name);
当然,这样在传递参数值的时候就可以不加‘%’了,当然加了也不会错
4.还有个很有意思的,就是这个例子:
@Query(value = "select * from Book b where b.name=?1", nativeQuery = true)
List<Book> findByName(String name);
// 此方法sql将会报错(java.lang.IllegalArgumentException),看出原因了吗,若没看出来,请看下一个例子
因为指定了nativeQuery = true,即使用原生的sql语句查询。使用java对象’Book’作为表名来查自然是不对的。只需将Book替换为表名book。因为若按数据库方法去查就找不到这张表了。
5.用SPEL表达式
public interface BookQueryRepositoryExample extends Repository<Book, Long>{
@Query(value = "select * from #{#entityName} b where b.name=?1", nativeQuery = true)
List<Book> findByName(String name);
}
@Query的方法都讲完了,仔细看看多做几个案例就可以完全熟悉这些操作。
接下来我们总结一下,如果不用@Query的话,jpa是怎么通过方法名来解析出对应sql的。
预先生成方法(默认自带方法)
spring data jpa 默认预先生成了一些基本的CURD的方法,例如:增、删、改等等
1 继承JpaRepository
public interface UserRepository extends JpaRepository<User, Long> {
}
既然是需要继承JpaRepository接口的话,那么自带封装的方法就是在这里面,
其实JpaRepository又继承于PagingAndSortingRepository,实现一组JPA规范相关的方法
PagingAndSortingRepository又继承于CrudRepository,实现了一组分页排序相关的方法
CrudRepository又继承于Repository,实现了一组CRUD相关的方法(主要是在这里)
Repository仅仅是一个标识,表明任何继承它的均为仓库接口类,方便Spring自动扫描识别。
JpaSpecificationExecutor: 比较特殊,不属于Repository体系,实现一组JPA Criteria查询相关的方法
我们自己定义的XxxxRepository需要继承JpaRepository,这样我们的XxxxRepository接口就具备了通用的数据访问控制层的能力。
-JpaRepository 所提供的基本功能 :
1.继承自CrudRepository<T, ID extends Serializable>
这个接口提供了最基本的对实体类的添删改查操作
T save(T entity);//保存单个实体
Iterable
T findOne(ID id);//根据id查找实体
boolean exists(ID id);//根据id判断实体是否存在
Iterable
long count();//查询实体数量
void delete(ID id);//根据Id删除实体
void delete(T entity);//删除一个实体
void delete(Iterable<? extends T> entities);//删除一个实体的集合
void deleteAll();//删除所有实体,不用或慎用!
2.继承自PagingAndSortingRepository<T, ID extends Serializable>
这个接口提供了分页与排序功能
Iterable
Page
3.本身JpaRepository<T, ID extends Serializable>
这个接口提供了JPA的相关功能
List
List
List
void flush();//执行缓存与数据库同步,flush的字面意思是刷新的意思。
T saveAndFlush(T entity);//强制执行持久化
void deleteInBatch(Iterable
2 使用默认方法
@Test
public void testBaseQuery() throws Exception {
User user=new User();
userRepository.findAll();
userRepository.findOne(1l);
userRepository.save(user);
userRepository.delete(user);
userRepository.count();
userRepository.exists(1l);
// ...
}
自定义简单查询
自定义的简单查询就是根据方法名来自动生成SQL,主要的语法是findXXBy,readAXXBy,queryXXBy,countXXBy, getXXBy后面跟属性名称:
User findByUserName(String userName);
也使用一些加一些关键字And、 Or
User findByUserNameOrEmail(String username, String email);
修改、删除、统计也是类似语法
Long deleteById(Long id);
Long countByUserName(String userName)
基本上SQL体系中的关键词都可以使用,例如:LIKE、 IgnoreCase、 OrderBy。
List<User> findByEmailLike(String email);
User findByUserNameIgnoreCase(String userName);
List<User> findByUserNameOrderByEmailDesc(String email);
具体的关键字,使用方法和生产成SQL如下表所示:
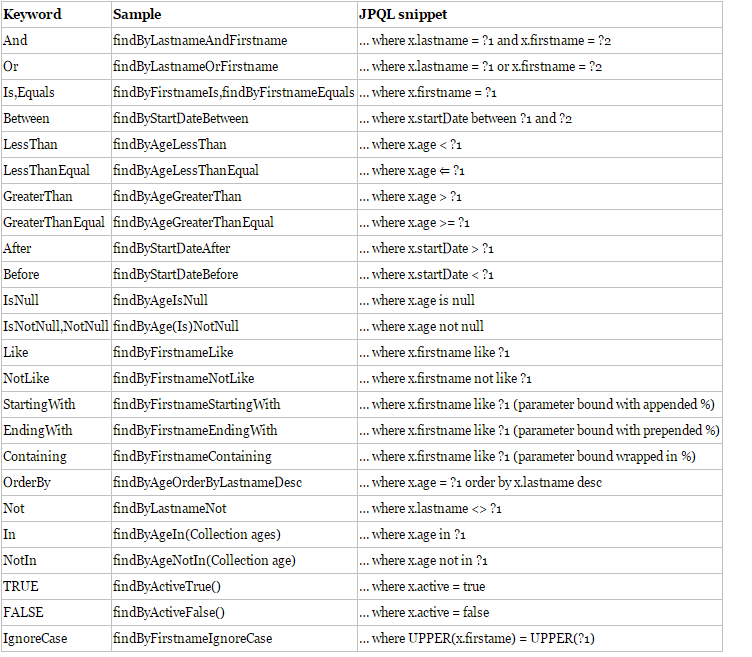
复杂查询
在实际的开发中我们需要用到分页、删选、连表等查询的时候就需要特殊的方法或者自定义SQL
分页查询
分页查询在实际使用中非常普遍了,spring data jpa已经帮我们实现了分页的功能,在查询的方法中,需要传入参数Pageable
,当查询中有多个参数的时候Pageable建议做为最后一个参数传入
Page<User> findALL(Pageable pageable);
Page<User> findByUserName(String userName,Pageable pageable);
Pageable 是spring封装的分页实现类,使用的时候需要传入页数、每页条数和排序规则
@Test
public void testPageQuery() throws Exception {
int page=1,size=10;
Sort sort = new Sort(Direction.DESC, "id");
Pageable pageable = new PageRequest(page, size, sort);
userRepository.findALL(pageable);
userRepository.findByUserName("testName", pageable);
}
限制查询
有时候我们只需要查询前N个元素,或者支取前一个实体。
User findFirstByOrderByLastnameAsc();
User findTopByOrderByAgeDesc();
Page<User> queryFirst10ByLastname(String lastname, Pageable pageable);
List<User> findFirst10ByLastname(String lastname, Sort sort);
List<User> findTop10ByLastname(String lastname, Pageable pageable);
多表查询
多表查询在spring data jpa中有两种实现方式,第一种是利用hibernate的级联查询来实现,第二种是创建一个结果集的接口来接收连表查询后的结果,这里主要第二种方式。
首先需要定义一个结果集的接口类。
public interface HotelSummary {
City getCity();
String getName();
Double getAverageRating();
default Integer getAverageRatingRounded() {
return getAverageRating() == null ? null : (int) Math.round(getAverageRating());
}
}
查询的方法返回类型设置为新创建的接口
@Query("select h.city as city, h.name as name, avg(r.rating) as averageRating "
- "from Hotel h left outer join h.reviews r where h.city = ?1 group by h")
Page<HotelSummary> findByCity(City city, Pageable pageable);
@Query("select h.name as name, avg(r.rating) as averageRating "
- "from Hotel h left outer join h.reviews r group by h")
Page<HotelSummary> findByCity(Pageable pageable);
使用
Page<HotelSummary> hotels = this.hotelRepository.findByCity(new PageRequest(0, 10, Direction.ASC, "name"));
for(HotelSummary summay:hotels){
System.out.println("Name" +summay.getName());
}
在运行中Spring会给接口(HotelSummary)自动生产一个代理类来接收返回的结果,代码汇总使用getXX的形式来获取。
多数据源的支持
多数据源即指的是多个数据库来源,实际开发中往往根据储存内容进行分库,专门储存用户信息,上传文件甚至是小数据(评论计数和密码等等),这就是多数据源的情况。
如何实现多数据源的配置呢?
创建一个Spring配置类,定义两个DataSource用来读取application.properties中的不同配置。如下例子中,主数据源配置为spring.datasource.primary开头的配置,第二数据源配置为spring.datasource.secondary开头的配置。
@Primary和@Qualifier这两个注解的意思:@Primary的意思是在众多相同的bean中,优先使用用@Primary注解的bean.而@Qualifier这个注解则指定某个bean有没有资格进行注入。
@Configuration
public class DataSourceConfig {
@Bean(name = "primaryDataSource")
@Qualifier("primaryDataSource")
@ConfigurationProperties(prefix="spring.datasource.primary")
public DataSource primaryDataSource() {
return DataSourceBuilder.create().build();
}
@Bean(name = "secondaryDataSource")
@Qualifier("secondaryDataSource")
@Primary
@ConfigurationProperties(prefix="spring.datasource.secondary")
public DataSource secondaryDataSource() {
return DataSourceBuilder.create().build();
}
}
对应的application.properties配置如下:(指向了test1和test2数据库)
spring.datasource.primary.url=jdbc:mysql://localhost:3306/test1
spring.datasource.primary.username=root
spring.datasource.primary.password=root
spring.datasource.primary.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.secondary.url=jdbc:mysql://localhost:3306/test2
spring.datasource.secondary.username=root
spring.datasource.secondary.password=root
spring.datasource.secondary.driver-class-name=com.mysql.jdbc.Driver
但是根据不同的持久化组件来说其注入方式也算不同的,接下来就是比较JdbcTemplate和Spring-data-jpa的注入方式的不同。
-JdbcTemplate支持
对JdbcTemplate的支持比较简单,只需要为其注入对应的datasource即可,如下例子,在创建JdbcTemplate的时候分别注入名为primaryDataSource和secondaryDataSource的数据源来区分不同的JdbcTemplate。
@Bean(name = "primaryJdbcTemplate")
public JdbcTemplate primaryJdbcTemplate(
@Qualifier("primaryDataSource") DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
@Bean(name = "secondaryJdbcTemplate")
public JdbcTemplate secondaryJdbcTemplate(
@Qualifier("secondaryDataSource") DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
接下来通过测试用例来演示如何使用这两个针对不同数据源的JdbcTemplate。
@RunWith(SpringJUnit4ClassRunner.class)
@SpringApplicationConfiguration(Application.class)
public class ApplicationTests {
@Autowired
@Qualifier("primaryJdbcTemplate")
protected JdbcTemplate jdbcTemplate1;
@Autowired
@Qualifier("secondaryJdbcTemplate")
protected JdbcTemplate jdbcTemplate2;
@Before
public void setUp() {
jdbcTemplate1.update("DELETE FROM USER ");
jdbcTemplate2.update("DELETE FROM USER ");
}
@Test
public void test() throws Exception {
// 往第一个数据源中插入两条数据
jdbcTemplate1.update("insert into user(id,name,age) values(?, ?, ?)", 1, "aaa", 20);
jdbcTemplate1.update("insert into user(id,name,age) values(?, ?, ?)", 2, "bbb", 30);
// 往第二个数据源中插入一条数据,若插入的是第一个数据源,则会主键冲突报错
jdbcTemplate2.update("insert into user(id,name,age) values(?, ?, ?)", 1, "aaa", 20);
// 查一下第一个数据源中是否有两条数据,验证插入是否成功
Assert.assertEquals("2", jdbcTemplate1.queryForObject("select count(1) from user", String.class));
// 查一下第一个数据源中是否有两条数据,验证插入是否成功
Assert.assertEquals("1", jdbcTemplate2.queryForObject("select count(1) from user", String.class));
}
}
-Spring-data-jpa支持
对于数据源的配置可以沿用上例中DataSourceConfig的实现。
primaryDataSource和secondaryDataSource都需要分别编写配置文件
PrimaryConfig如下:
@Configuration
@EnableTransactionManagement
@EnableJpaRepositories(
entityManagerFactoryRef="entityManagerFactoryPrimary",
transactionManagerRef="transactionManagerPrimary",
basePackages= { "com.didispace.domain.p" }) //设置Repository所在位置
public class PrimaryConfig {
@Autowired @Qualifier("primaryDataSource")
private DataSource primaryDataSource;
@Primary
@Bean(name = "entityManagerPrimary")
public EntityManager entityManager(EntityManagerFactoryBuilder builder) {
return entityManagerFactoryPrimary(builder).getObject().createEntityManager();
}
@Primary
@Bean(name = "entityManagerFactoryPrimary")
public LocalContainerEntityManagerFactoryBean entityManagerFactoryPrimary (EntityManagerFactoryBuilder builder) {
return builder
.dataSource(primaryDataSource)
.properties(getVendorProperties(primaryDataSource))
.packages("com.didispace.domain.p") //设置实体类所在位置
.persistenceUnit("primaryPersistenceUnit")
.build();
}
@Autowired
private JpaProperties jpaProperties;
private Map<String, String> getVendorProperties(DataSource dataSource) {
return jpaProperties.getHibernateProperties(dataSource);
}
@Primary
@Bean(name = "transactionManagerPrimary")
public PlatformTransactionManager transactionManagerPrimary(EntityManagerFactoryBuilder builder) {
return new JpaTransactionManager(entityManagerFactoryPrimary(builder).getObject());
}
}
新增对第二数据源的JPA配置,内容与第一数据源类似,具体如下,SecondaryConfig:
@Configuration
@EnableTransactionManagement
@EnableJpaRepositories(
entityManagerFactoryRef="entityManagerFactorySecondary",
transactionManagerRef="transactionManagerSecondary",
basePackages= { "com.didispace.domain.s" }) //设置Repository所在位置
public class SecondaryConfig {
@Autowired @Qualifier("secondaryDataSource")
private DataSource secondaryDataSource;
@Bean(name = "entityManagerSecondary")
public EntityManager entityManager(EntityManagerFactoryBuilder builder) {
return entityManagerFactorySecondary(builder).getObject().createEntityManager();
}
@Bean(name = "entityManagerFactorySecondary")
public LocalContainerEntityManagerFactoryBean entityManagerFactorySecondary (EntityManagerFactoryBuilder builder) {
return builder
.dataSource(secondaryDataSource)
.properties(getVendorProperties(secondaryDataSource))
.packages("com.didispace.domain.s") //设置实体类所在位置
.persistenceUnit("secondaryPersistenceUnit")
.build();
}
@Autowired
private JpaProperties jpaProperties;
private Map<String, String> getVendorProperties(DataSource dataSource) {
return jpaProperties.getHibernateProperties(dataSource);
}
@Bean(name = "transactionManagerSecondary")
PlatformTransactionManager transactionManagerSecondary(EntityManagerFactoryBuilder builder) {
return new JpaTransactionManager(entityManagerFactorySecondary(builder).getObject());
}
}
完成了以上配置之后,
主数据源的实体和数据访问对象位于:com.didispace.domain.p,
次数据源的实体和数据访问接口位于:com.didispace.domain.s。
分别在这两个package下创建各自的实体和数据访问接口
主数据源下,创建User实体和对应的Repository接口:
@Entity
public class User {
@Id
@GeneratedValue
private Long id;
@Column(nullable = false)
private String name;
@Column(nullable = false)
private Integer age;
public User(){}
public User(String name, Integer age) {
this.name = name;
this.age = age;
}
// 省略getter、setter
}
public interface UserRepository extends JpaRepository<User, Long> {
}
从数据源下,创建Message实体和对应的Repository接口:
@Entity
public class Message {
@Id
@GeneratedValue
private Long id;
@Column(nullable = false)
private String name;
@Column(nullable = false)
private String content;
public Message(){}
public Message(String name, String content) {
this.name = name;
this.content = content;
}
// 省略getter、setter
}
public interface MessageRepository extends JpaRepository<Message, Long> {
}
接下来通过测试用例来验证使用这两个针对不同数据源的配置进行数据操作。
@RunWith(SpringJUnit4ClassRunner.class)
@SpringApplicationConfiguration(Application.class)
public class ApplicationTests {
@Autowired
private UserRepository userRepository;
@Autowired
private MessageRepository messageRepository;
@Test
public void test() throws Exception {
//主数据源测试
userRepository.save(new User("aaa", 10));
userRepository.save(new User("bbb", 20));
userRepository.save(new User("ccc", 30));
userRepository.save(new User("ddd", 40));
userRepository.save(new User("eee", 50));
Assert.assertEquals(5, userRepository.findAll().size());
//从数据源测试
messageRepository.save(new Message("o1", "aaaaaaaaaa"));
messageRepository.save(new Message("o2", "bbbbbbbbbb"));
messageRepository.save(new Message("o3", "cccccccccc"));
Assert.assertEquals(3, messageRepository.findAll().size());
}
}
多数据源下的事务管理,只需要只需要通过value属性指定配置的事务管理器名即可,比如上面的PrimaryConfig和SecondaryConfig中配置了transactionManagerRef属性值,我们只要去声明即可:
@Transactional(value=”transactionManagerPrimary”)
除了指定不同的事务管理器之后,还能对事务进行隔离级别和传播行为的控制,下面分别详细解释:
-隔离级别
隔离级别是指若干个并发的事务之间的隔离程度,与我们开发时候主要相关的场景包括:脏读取、重复读、幻读。
我们可以看org.springframework.transaction.annotation.Isolation枚举类中定义了五个表示隔离级别的值:
public enum Isolation {
DEFAULT(-1),
READ_UNCOMMITTED(1),
READ_COMMITTED(2),
REPEATABLE_READ(4),
SERIALIZABLE(8);
}
DEFAULT:这是默认值,表示使用底层数据库的默认隔离级别。对大部分数据库而言,通常这值就是:READ_COMMITTED。
READ_UNCOMMITTED:该隔离级别表示一个事务可以读取另一个事务修改但还没有提交的数据。该级别不能防止脏读和不可重复读,因此很少使用该隔离级别。
READ_COMMITTED:该隔离级别表示一个事务只能读取另一个事务已经提交的数据。该级别可以防止脏读,这也是大多数情况下的推荐值。
REPEATABLE_READ:该隔离级别表示一个事务在整个过程中可以多次重复执行某个查询,并且每次返回的记录都相同。即使在多次查询之间有新增的数据满足该查询,这些新增的记录也会被忽略。该级别可以防止脏读和不可重复读。
SERIALIZABLE:所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
指定方法:通过使用isolation属性设置,例如:
@Transactional(isolation = Isolation.DEFAULT)
-传播行为
所谓事务的传播行为是指,如果在开始当前事务之前,一个事务上下文已经存在,此时有若干选项可以指定一个事务性方法的执行行为。
我们可以看org.springframework.transaction.annotation.Propagation枚举类中定义了6个表示传播行为的枚举值:
public enum Propagation {
REQUIRED(0),
SUPPORTS(1),
MANDATORY(2),
REQUIRES_NEW(3),
NOT_SUPPORTED(4),
NEVER(5),
NESTED(6);
}
REQUIRED:如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
MANDATORY:如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
REQUIRES_NEW:创建一个新的事务,如果当前存在事务,则把当前事务挂起。
NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,则把当前事务挂起。
NEVER:以非事务方式运行,如果当前存在事务,则抛出异常。
NESTED:如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于REQUIRED。
指定方法:通过使用propagation属性设置,例如:
@Transactional(propagation = Propagation.REQUIRED)
同源数据库的多源支持
日常项目中因为使用的分布式开发模式,不同的服务有不同的数据源,常常需要在一个项目中使用多个数据源,因此需要配置sping data jpa对多数据源的使用,一般分一下为三步:
1 配置多数据源
2 不同源的实体类放入不同包路径
3 声明不同的包路径下使用不同的数据源、事务支持
参考文章:https://www.jianshu.com/p/34730e595a8c
异构数据库多源支持
比如我们的项目中,即需要对mysql的支持,也需要对mongodb的查询等。
实体类声明@Entity 关系型数据库支持类型、声明@Document 为mongodb支持类型,不同的数据源使用不同的实体就可以了
interface PersonRepository extends Repository<Person, Long> {
…
}
@Entity
public class Person {
…
}
interface UserRepository extends Repository<User, Long> {
…
}
@Document
public class User {
…
}
但是,如果User用户既使用mysql也使用mongodb呢,也可以做混合使用
interface JpaPersonRepository extends Repository<Person, Long> {
…
}
interface MongoDBPersonRepository extends Repository<Person, Long> {
…
}
@Entity
@Document
public class Person {
…
}
也可以通过对不同的包路径进行声明,比如A包路径下使用mysql,B包路径下使用mongoDB
@EnableJpaRepositories(basePackages = “com.neo.repositories.jpa”)
@EnableMongoRepositories(basePackages = “com.neo.repositories.mongo”)
interface Configuration { }
其它
使用枚举
使用枚举的时候,我们希望数据库中存储的是枚举对应的String类型,而不是枚举的索引值,需要在属性上面添加@Enumerated(EnumType.STRING) 注解
@Enumerated(EnumType.STRING)
@Column(nullable = true)
private UserType type;
不需要和数据库映射的属性
正常情况下我们在实体类上加入注解@Entity,就会让实体类和表相关连如果其中某个属性我们不需要和数据库来关联只是在展示的时候做计算,只需要加上@Transient属性既可。
@Transient
private String userName;
参考项目:https://github.com/cloudfavorites/favorites-web (用到所有标签和注解)
spring-data-jpa中文开发文档:https://legacy.gitbook.com/book/ityouknow/spring-data-jpa-reference-documentation/details
踩坑史:

