多为总结网上分析对比的经验,以统一的Mysql数据库为例,分析各种流行的数据库连接池技术的使用场景及优劣。
对现有的数据库连接池做调研对比,综合性能,可靠性,稳定性,扩展性等因素选出推荐出最优的数据库连接池 。
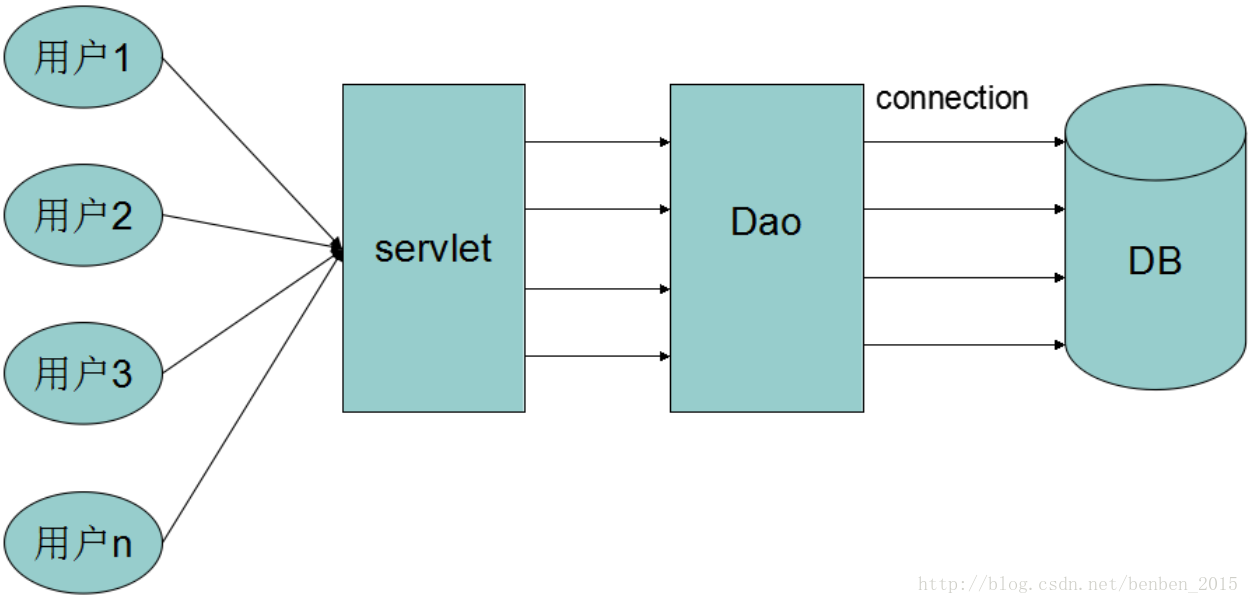
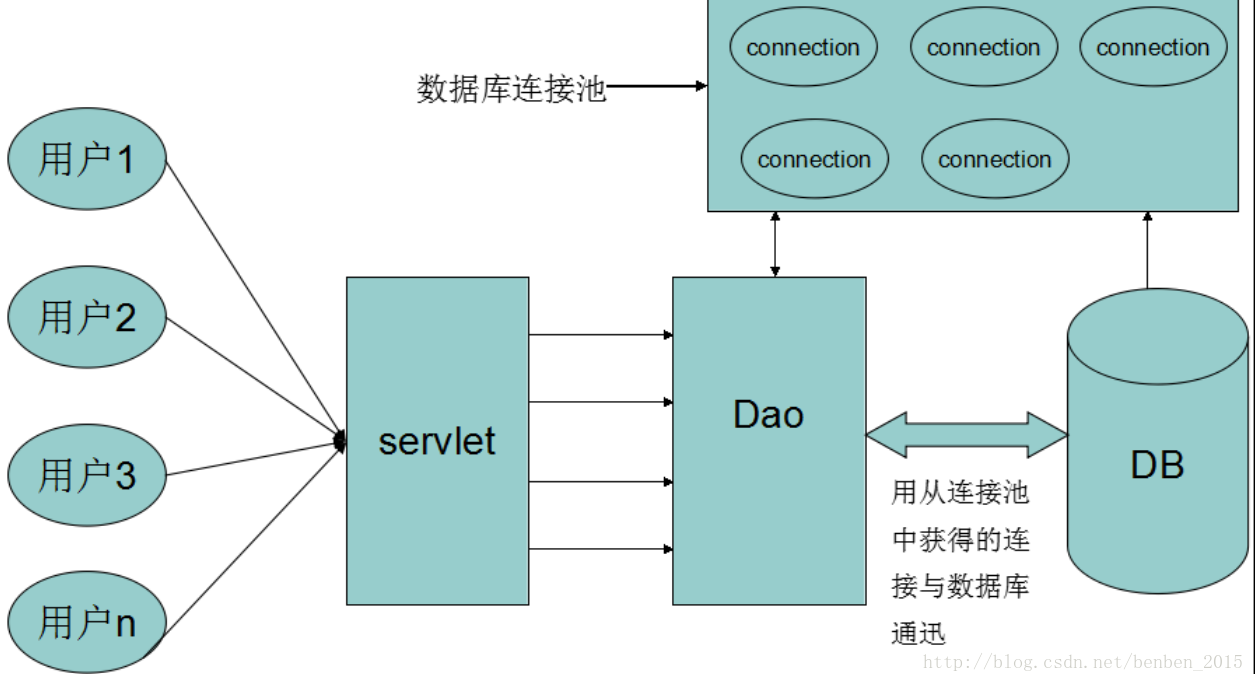
数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个;释放空闲时间超过最大空闲时间的数据库连接来避免因为没有释放数据库连接而引起的数据库连接遗漏。这项技术能明显提高对数据库操作的性能。使用数据库连接池后就不是服务器直接和数据库进行直接交互,而是由连接池管理服务器的连接请求,各个数据库连接池有不同的原理和连接策略。
数据库连接池
1、C3P0:是一个开放源代码的JDBC连接池,它在lib目录中与Hibernate [2] 一起发布,包括了实现jdbc3和jdbc2扩展规范说明的Connection 和Statement 池的DataSources 对象。
2、BoneCP:是一个快速、开源的数据库连接池。帮用户管理数据连接,让应用程序能更快速地访问数据库。比C3P0/DBCP连接池速度快25倍。这已经足够快了。
3、Druid:Druid不仅是一个数据库连接池,还包含一个ProxyDriver、一系列内置的JDBC组件库、一个SQL Parser。
支持所有JDBC兼容的数据库,包括Oracle、MySql、Derby、Postgresql、SQL Server、H2等。
Druid针对Oracle和MySql做了特别优化,比如:
Oracle的PS Cache内存占用优化
MySql的ping检测优化
Druid提供了MySql、Oracle、Postgresql、SQL-92的SQL的完整支持,这是一个手写的高性能SQL Parser,支持Visitor模式,使得分析SQL的抽象语法树很方便。简单SQL语句用时10微秒以内,复杂SQL用时30微秒。通过Druid提供的SQL Parser可以在JDBC层拦截SQL做相应处理,比如说分库分表、审计等。Druid防御SQL注入攻击的WallFilter,就是通过Druid的SQL Parser分析语义实现的。
4、HiKariCP是数据库连接池的一个后起之秀,号称性能最好,可以完美地PK掉其他连接池。Hikari来自日文,是“光”(阳光的光,不是光秃秃的光)的意思。作者估计是为了借助这个词来暗示这个CP速度飞快。
参考比较:https://blog.csdn.net/fly_boss/article/details/60965849
https://blog.csdn.net/jiesa/article/details/73849243
测试结论:
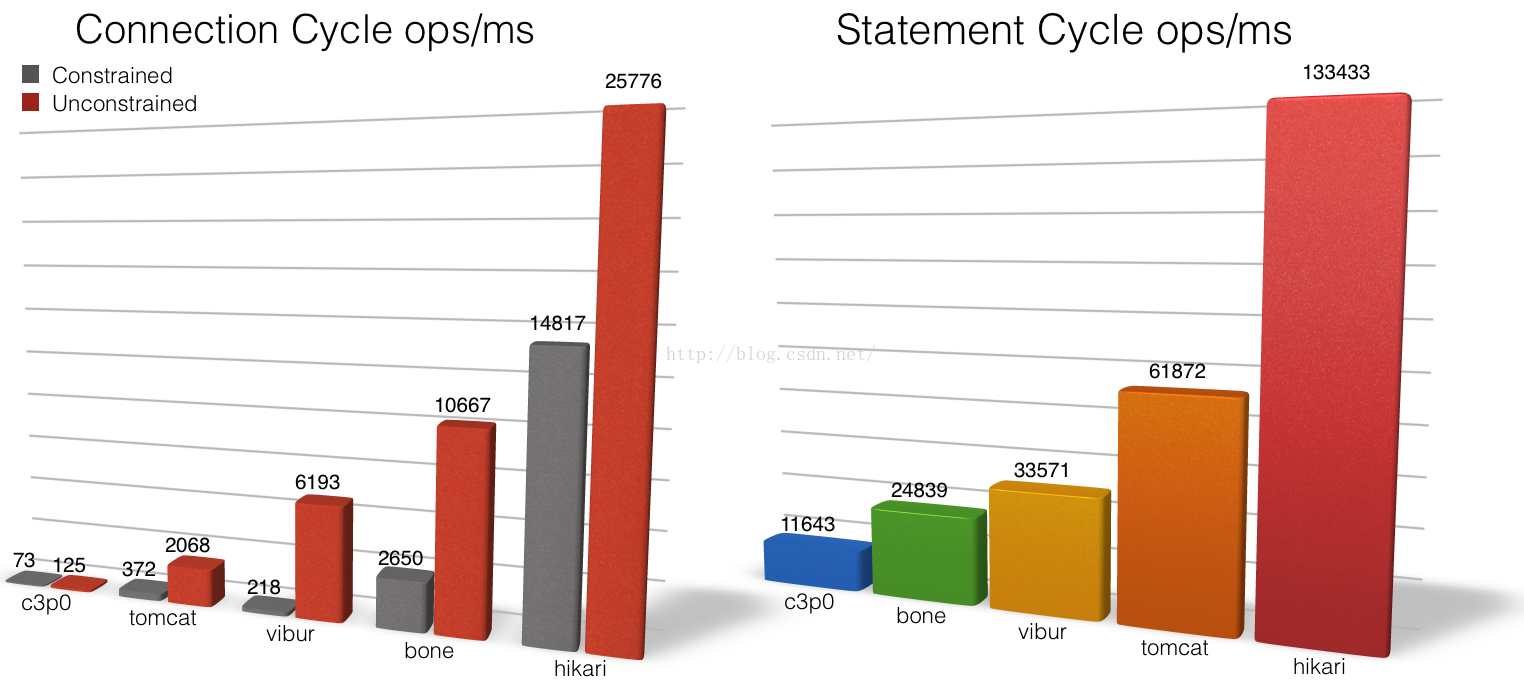
1:性能方面 hikariCP>druid>tomcat-jdbc>dbcp>c3p0 。hikariCP的高性能得益于最大限度的避免锁竞争。
2:druid功能最为全面,sql拦截等功能,统计数据较为全面,具有良好的扩展性。
3:综合性能,扩展性等方面,可考虑使用druid或者hikariCP连接池。
4:可开启prepareStatement缓存,对性能会有大概20%的提升。
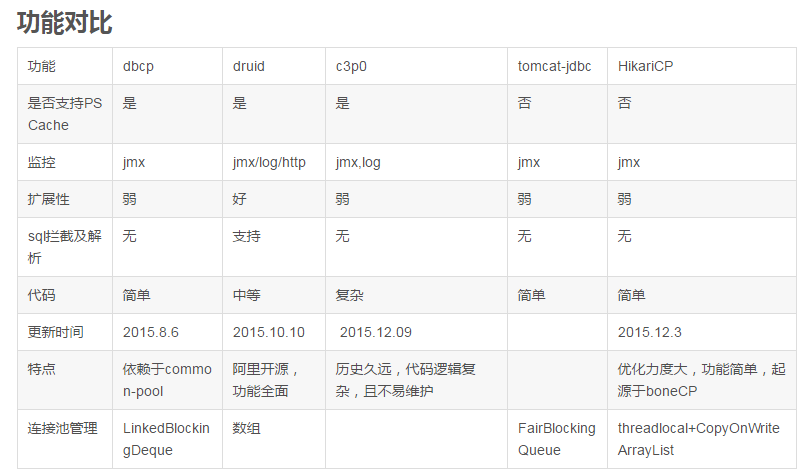
由于boneCP被hikariCP替代,并且已经不再更新,boneCP没有进行调研。
proxool网上有评测说在并发较高的情况下会出错,proxool便没有进行调研。(问题之一在并发获取连接时会有问题 http://blog.csdn.net/jiesa/article/details/73823621)
druid的功能比较全面,且扩展性较好,比较方便对jdbc接口进行监控跟踪等。
c3p0历史悠久,代码及其复杂,不利于维护。并且存在deadlock的潜在风险。
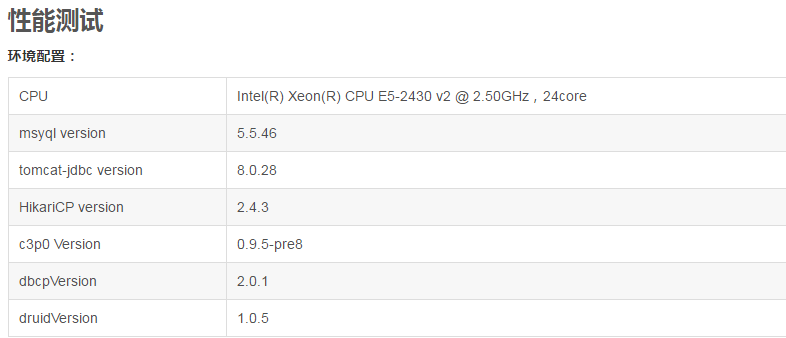
(1)测试一:获取关闭连接性能测试
测试说明:
初始连接和最小连接均为5,最大连接为20。在borrow和return均不心跳检测
其中打开关闭次数为: 100w次
测试用例和mysql在同一台机器上面,尽量避免io的影响
使用mock和连接mysql在不同线程并发下的响应时间
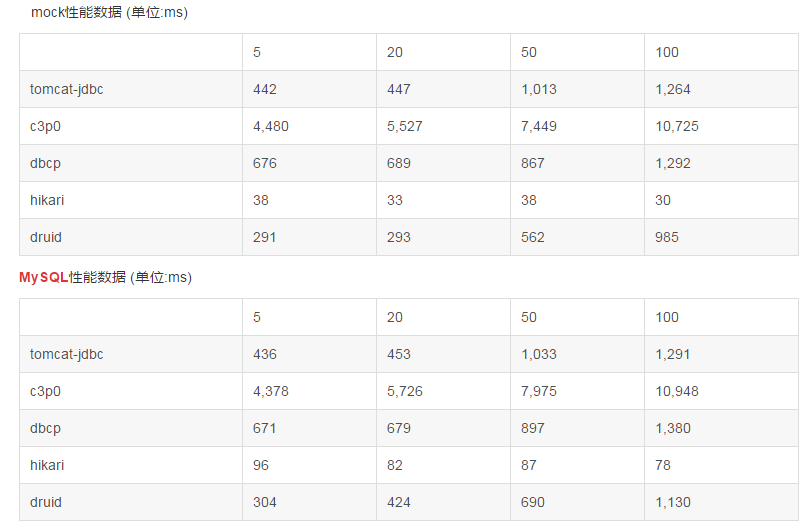
测试结果:
mock和mysql连接性能表现差不多,主要是由于初始化的时候建立了连接后期不再建立连接,和使用mock连接逻辑一致。
性能表现:hikariCP>druid>tomcat-jdbc>dbcp>c3p0。
hikariCP 的性能及其优异。hikariCP号称java平台最快的数据库连接池。
hikariCP在并发较高的情况下,性能基本上没有下降。
c3p0连接池的性能很差,不建议使用该数据库连接池。
hikariCP性能分析:
hikariCP通过优化(concurrentBag,fastStatementList )集合来提高并发的读写效率。
hikariCP使用threadlocal缓存连接及大量使用CAS的机制,最大限度的避免lock。单可能带来cpu使用率的上升。
从字节码的维度优化代码。 (default inline threshold for a JVM running the server Hotspot compiler is 35 bytecodes )让方法尽量在35个字节码一下,来提升jvm的处理效率。
(2)测试二:查询一条语句性能测试
测试说明:
初始连接和最小连接均为8,最大连接为8。在borrow和return均不心跳检测
查询的次数为10w次,查询的语句为 1:打开连接 2:执行 :select 1 3:关闭连接
测试用例和mysql在同一台机器上面,尽量避免io的影响
测试结果:
在并发比较少的情况下,每个连接池的响应时间差不多。是由于并发少,基本上没有资源竞争。
在并发较高的情况下,随着并发的升高,hikariCP响应时间基本上没有变动。
c3p0随着并发的提高,性能急剧下降。
(3)测试三:pscache性能对比
测试说明:
通过druid进行设置pscache和不设置pscache的性能对比
初始连接和最小连接均为8,最大连接为8。在borrow和return均不心跳检测。并且执行的并发数为8.
查询10w次。查询流程为:1:建立连接,2:循环查询preparestatement语句 3:close连接
测试用例和mysql在同一台机器上面,尽量避免io的影响。
试数据:
cache 1,927
not cache 2,134
测试结果:
开启psCache缓存,性能大概有20%幅度的提升。可考虑开启pscache.
测试说明:
psCache是connection私有的,所以不存在线程竞争的问题,开启pscache不会存在竞争的性能损耗。
psCache的key为prepare执行的sql和catalog等,value对应的为prepareStatement对象。开启缓存主要是减少了解析sql的开销。
HikariCP在Github上的开源:https://github.com/brettwooldridge/HikariCP
Springboot与hakariCP
官网详细地说明了HikariCP所做的一些优化,总结如下:
字节码精简:优化代码,直到编译后的字节码最少,这样,CPU缓存可以加载更多的程序代码;
优化代理和拦截器:减少代码,例如HikariCP的Statement proxy只有100行代码,只有BoneCP的十分之一;
自定义数组类型(FastStatementList)代替ArrayList:避免每次get()调用都要进行range check,避免调用remove()时的从头到尾的扫描;
自定义集合类型(ConcurrentBag):提高并发读写的效率;
其他针对BoneCP缺陷的优化,比如对于耗时超过一个CPU时间片的方法调用的研究(但没说具体怎么优化)。
很多优化的对比都是针对BoneCP的……哈哈。
(参考文章:https://github.com/brettwooldridge/HikariCP/wiki/Down-the-Rabbit-Hole)
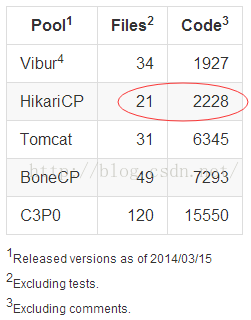
几个连接池的代码量对比(代码量越少,一般意味着执行效率越高、发生bug的可能性越低):
hikari的代码量最少,文件最小
另外,关于可靠性方面,也是有实验和数据支持的。对于数据库连接中断的情况,通过测试getConnection(),各种CP的不相同处理方法如下:
(所有CP都配置了跟connectionTimeout类似的参数为5秒钟)
HikariCP:等待5秒钟后,如果连接还是没有恢复,则抛出一个SQLExceptions 异常;后续的getConnection()也是一样处理;
C3P0:完全没有反应,没有提示,也不会在“CheckoutTimeout”配置的时长超时后有任何通知给调用者;然后等待2分钟后终于醒来了,返回一个error;
Tomcat:返回一个connection,然后……调用者如果利用这个无效的connection执行SQL语句……结果可想而知;大约55秒之后终于醒来了,这时候的getConnection()终于可以返回一个error,但没有等待参数配置的5秒钟,而是立即返回error;
BoneCP:跟Tomcat的处理方法一样;也是大约55秒之后才醒来,有了正常的反应,并且终于会等待5秒钟之后返回error了;
可见,HikariCP的处理方式是最合理的。根据这个测试结果,对于各个CP处理数据库中断的情况,评分如下:
HiKariCP的数据源配置:
<!-- Hikari Datasource -->
<bean id="dataSourceHikari" class="com.zaxxer.hikari.HikariDataSource" destroy-method="shutdown">
<!-- <property name="driverClassName" value="${db.driverClass}" /> --> <!-- 无需指定,除非系统无法自动识别 -->
<property name="jdbcUrl" value="jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8" />
<property name="username" value="${db.username}" />
<property name="password" value="${db.password}" />
<!-- 连接只读数据库时配置为true, 保证安全 -->
<property name="readOnly" value="false" />
<!-- 等待连接池分配连接的最大时长(毫秒),超过这个时长还没可用的连接则发生SQLException, 缺省:30秒 -->
<property name="connectionTimeout" value="30000" />
<!-- 一个连接idle状态的最大时长(毫秒),超时则被释放(retired),缺省:10分钟 -->
<property name="idleTimeout" value="600000" />
<!-- 一个连接的生命时长(毫秒),超时而且没被使用则被释放(retired),缺省:30分钟,建议设置比数据库超时时长少30秒,参考MySQL wait_timeout参数(show variables like '%timeout%';) -->
<property name="maxLifetime" value="1800000" />
<!-- 连接池中允许的最大连接数。缺省值:10;推荐的公式:((core_count * 2) + effective_spindle_count) -->
<property name="maximumPoolSize" value="15" />
</bean>
其中,很多配置都使用缺省值就行了,除了maxLifetime和maximumPoolSize要注意自己计算一下。
其他的配置(sqlSessionFactory、MyBatis MapperScannerConfigurer、transactionManager等)统统不用变。
其他关于Datasource配置参数的建议:
Configure your HikariCP idleTimeout and maxLifeTime settings to be one minute less than the wait_timeout of MySQL.
对于有Java连接池的系统,建议MySQL的wait_timeout使用缺省的8小时(http://www.rackspace.com/knowledge_center/article/how-to-change-the-mysql-timeout-on-a-server)。
另外:对于web项目,记得要配置:destroy-method=”shutdown” ,关闭连接池的时候释放连接资源。
HiKariCP数据库连接池号称目前是最快的, HikariCP VS druid VS c3p0 VS dbcp VS jdbc 数据库连接池性能比对
性能方面 hikariCP>druid>tomcat-jdbc>dbcp>c3p0,hikariCP的高性能得益于最大限度的避免锁竞争。
druid功能最为全面,sql拦截等功能,统计数据较为全面,具有良好的扩展性。
综合性能,扩展性等方面,可考虑使用druid或者hikariCP连接池。
可开启prepareStatement缓存,对性能会有大概20%的提升
现在来用Spring Cloud 配置HikariCP数据库连接池:
我们用实际开发中比较常见的项目技术架构:springboot+hikariCP+mybatis+mysql来说明DEMO。
第一步:导包,首先我们使用mybatis-spring-boot-starter时,这个包内自动配置了tomcat-jdbc连接池,所以我们要想用hikariCP,需要把原来的连接池给去掉,不然会冲突。
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.3.1</version>
<!-- 排除tomcat jdbc 原有的-->
<exclusions>
<exclusion>
<groupId>org.apache.tomcat</groupId>
<artifactId>tomcat-jdbc</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- HikariCP -->
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>2.7.4</version>
</dependency>
<!-- Mysql连接支持 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.39</version>
</dependency>
第二步:在HiKariCP数据库连接池配置如下:(自然有java配置和xml配置,properties文件配置三种)
在spring框架中,经常将连接池的设置参数独立成一个.properties文件,它可以根据客户需求,自定义一些相关的参数。我们这里推荐用.properties来定义数据库连接池的参数,然后在配置文件中取properties文件中的参数即可,一是这样也统一了参数配置数据,二是多环境配置中我们可以很好的切换参数列表,不用直接修改代码。
一般都会有application.properties为主要文件,在里面通过设置spring.profiles.active属性对应到application-dev.properties,application-test.properties,application-prod.properties文件上,根据场景的不同直接在命令行进行切换,不管是开发人员,测试人员还是运维人员都可以通过简单的命令去设置哪个文件。
在properties文件中配置参数:
`#HikariDataSource config`
hikaricp.jdbc.driverClassName=com.mysql.jdbc.Driver
hikaricp.url= jdbc:mysql://127.0.0.1:3306/dcserver38useUnicode=true&characterEncoding=UTF-8
hikaricp.quratz_jdbc.url=jdbc:mysql://127.0.0.1:3306/quartz?useUnicode=true&characterEncoding=UTF-8
hikaricp.username=root
hikaricp.password=123456
hikaricp.connectionTestQuery= SELECT 1
//等待连接池分配连接的最大时长(毫秒),超过这个时长还没可用的连接则发生SQLException, 缺省:30秒
hikaricp.connectionTimeout = 30000
//一个连接idle状态的最大时长(毫秒),超时则被释放(retired),缺省:10分钟
hikaricp.idleTimeout = 600000
// 一个连接的生命时长(毫秒),超时而且没被使用则被释放(retired),缺省:30分钟,建议设置比数据库超时时长少30秒,参考MySQL wait_timeout参数(show variables like '%timeout%';)
hikaricp.maxLifetime = 1800000
//池连接数量
//连接池中允许的最大连接数。缺省值:10;推荐的公式:((core_count * 2) + effective_spindle_count)
hikaricp.maximumPoolSize =100
hikaricp.minimumIdle =100
XML配置(取这个.properties文件中的值),完成配置HikariCPConfig.xml
<bean id="hikariDataSource"
class="com.zaxxer.hikari.HikariDataSource" destroy-method="shutdown">
<constructor-arg>
<bean class="com.zaxxer.hikari.HikariConfig">
<property name="driverClassName" value="${hikaricp.jdbc.driverClassName}"/>
<property name="jdbcUrl" value="${hikaricp.url}"/>
<property name="username" value="${hikaricp.username}"/>
<property name="password" value="${hikaricp.password}"/>
<property name="connectionTestQuery" value="${hikaricp.connectionTestQuery}"/>
<property name="connectionTimeout" value="${hikaricp.connectionTimeout}"/>
<property name="idleTimeout" value="${hikaricp.idleTimeout}"/>
<property name="maxLifetime" value="${hikaricp.maxLifetime}"/>
<property name="maximumPoolSize" value="${hikaricp.maximumPoolSize}"/>
<property name="minimumIdle" value="${hikaricp.minimumIdle}"/>
</bean>
</constructor-arg>
</bean>
第三步:完成这个配置后,在application.properties中配置好这个bean即可,声明给springboot管理。
因为新版的springboot支持三种数据库连接池的直接配置:DBCP(DBCP2),tomcat-JDBC(就是mybatis自带哪个),HikariCP。
Spring-Boot配置文件数据源配置项常见如下:
参数 介绍
spring.datasource.continue-on-error = false 初始化数据库时发生错误时,请勿停止
spring.datasource.data = Data(DML)脚本资源引用
spring.datasource.data-username = 执行DML脚本(如果不同)的数据库用户
spring.datasource.data-password = 执行DML脚本的数据库密码(如果不同)
spring.datasource.dbcp2. = Commons DBCP2具体设置(DBCP)
spring.datasource.driver-class-name JDBC驱动程序的完全限定名称默认情况下,根据 URL自动检测
spring.datasource.generate-unique-name = false 生成随机数据源名称
spring.datasource.hikari. = Hikari具体设置(HikariCP)
spring.datasource.initialize = true 使用’data.sql’填充数据库
spring.datasource.jmx-enabled = false 启用JMX支持(如果基础池提供)
spring.datasource.jndi-name = 数据源的JNDI位置。设置时,类,网址,用户名 和密码将被忽略
spring.datasource.name = testdb 数据源的名称
spring.datasource.password 登录数据库的密码
spring.datasource.platform =所有 在架构资源中使用的平台(schema - $ {platform} .sql)
spring.datasource.schema = Schema(DDL)脚本资源引用
spring.datasource.schema-username = 数据库用户执行DDL脚本(如果不同)
spring.datasource.schema-password = 执行DDL脚本的数据库密码(如果不同)
spring.datasource.separator =; 语句分隔符在SQL初始化脚本中
spring.datasource.sql-script-encoding = SQL脚本编码
spring.datasource.tomcat.* = Tomcat数据源特定设置(tomcat-jdbc)
spring.datasource.type = 要使用的连接池实现的完全限定名称。默认情况 下,它是从类路径自动检测的
spring.datasource.url 数据库的JDBC url
spring.datasource.username 登录数据库的用户
spring.datasource.xa.data-source-class-name = XA datasource全限定名
spring.datasource.xa.properties = 传递给XA数据源的属性。
我们只需要按照要求配置spring.datasource.hikari.* =即可
把刚刚我们配置好的bean的id写进来,大功告成,可以使用HikariCP了!!性能将大大提升!
spring.datasource.hikari.* =hikariDataSource
好像除了这个方法,在网上还看到了用.yml文件直接配置HikariCP的案例:
代码配置如下:(application.yml文件)
spring:
profiles:
active: dev
datasource:
driver-class-name: com.mysql.jdbc.Driver
username: root
password: 123456
hikari:
maxLifetime: 1765000 #一个连接的生命时长(毫秒),超时而且没被使用则被释放(retired),缺省:30分钟,建议设置比数据库超时时长少30秒以上
maximumPoolSize: 15 #连接池中允许的最大连接数。缺省值:10;推荐的公式:((core_count * 2) + effective_spindle_count)
mybatis:
mapperLocations: classpath:mapper/*.xml
---
// 开发环境配置
spring:
profiles: dev
datasource:
url: jdbc:mysql://localhost:3306/
---
// 测试环境配置
spring:
profiles: test
datasource:
url: jdbc:mysql://192.168.0.12:3306/
---
// 生产环境配置
spring:
profiles: prod
datasource:
url: jdbc:mysql://192.168.0.13:3306/

