传统线程及并发处理
关于同步及互斥,对象锁与类锁,wait(),notify(),notifyAll()这三种方法怎么用这是最关键的问题。
wait,notify,notifyAll 是定义在Object类的实例方法,用于控制线程状态。
三个方法都必须在synchronized 同步关键字所限定的作用域中调用,否则会报错java.lang.IllegalMonitorStateException ,意思是因为没有同步,所以线程对对象锁的状态是不确定的,不能调用这些方法。
wait 表示持有对象锁的线程A准备释放对象锁权限,释放cpu资源并进入等待。
notify 表示持有对象锁的线程A准备释放对象锁权限,通知jvm唤醒某个竞争该对象锁的线程X。线程A synchronized 代码作用域结束后,线程X直接获得对象锁权限,其他竞争线程继续等待(即使线程X同步完毕,释放对象锁,其他竞争线程仍然等待,直至有新的notify ,notifyAll被调用)。
notifyAll 表示持有对象锁的线程A准备释放对象锁权限,通知jvm唤醒所有竞争该对象锁的线程,线程A synchronized 代码作用域结束后,jvm通过算法将对象锁权限指派给某个线程X,所有被唤醒的线程不再等待。线程X synchronized 代码作用域结束后,之前所有被唤醒的线程都有可能获得该对象锁权限,这个由JVM算法决定。
wait有三个重载方法,同时必须捕获非运行时异常InterruptedException。
wait() 进入等待,需要notify ,notifyAll才能唤醒
wait(long timeout) 进入等待,经过timeout 超时后,若未被唤醒,则自动唤醒
wait(timeout, nanos) 进入等待,经过timeout 超时后,若未被唤醒,则自动唤醒。相对wait(long timeout) 更加精确时间。
那么对象锁又是什么?类锁又是啥?
synchronized关键字
synchronized关键字有如下两种用法:
1、 在需要同步的方法的方法签名中加入synchronized关键字。
在非静态方法中加入synchronized关键字是对象级别的
synchronized public void getValue() {
System.out.println("getValue method thread name="
+ Thread.currentThread().getName() + " username=" + username
+ " password=" + password);
}
上面的代码修饰的synchronized是非静态方法,如果修饰的是静态方法(static)含义是完全不一样的。具体不一样在哪里,后面会详细说清楚。
而在静态方法中加入synchronized关键字是类级别的(静态方法是类直接调用的)
synchronized static public void getValue() {
System.out.println(“getValue method thread name=”
+ Thread.currentThread().getName() + " username=" + username
+ " password=" + password);
}
2、使用synchronized块对需要进行同步的代码段进行同步。
因为同步是对系统开销很大的一种操作,若是要执行高并发就必须要用到同步,因此为了尽量减少同步的内容要用到同步块,对方法里的一部分进行加锁。
同步块所锁住的参数也是对应不同的级别
同步代码块的synchronized (this)用法和synchronized (非this对象)的用法锁的是对象
同步代码块的synchronized (类.class)用法锁的是类
包括上面所声明的在方法前加关键字,syncronized总共有5种方法
public void serviceMethod() {
try {
synchronized (this) {
System.out.println("begin time=" + System.currentTimeMillis());
Thread.sleep(2000);
System.out.println("end end=" + System.currentTimeMillis());
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
上面的代码块是synchronized (this)用法,还有synchronized (非this对象)以及synchronized (类.class)这两种用法,这些使用方式的含义也是有根本的区别的。我们先带着这些问题继续往下看。
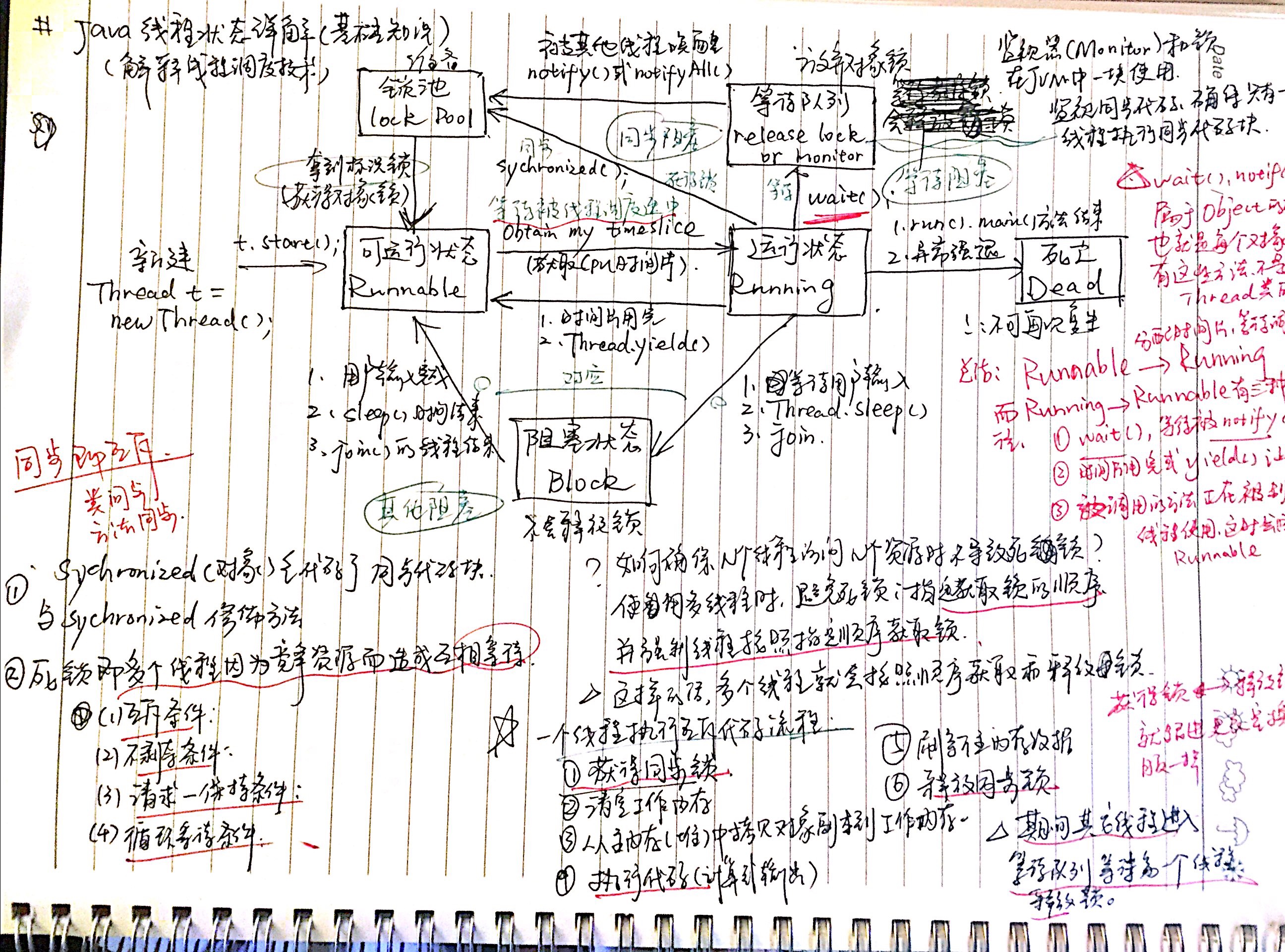
1.一段synchronized的代码被一个线程执行之前,他要先拿到执行这段代码的权限;(执行代码的权限就是对象锁)
2.在Java里边就是拿到某个同步对象的锁(一个对象只有一把锁);
3.如果这个时候同步对象的锁被其他线程拿走了,他(这个线程)就只能等了(线程阻塞在锁池等待队列中)。
4.取到锁后,他就开始执行同步代码(被synchronized修饰的代码);
5.线程执行完同步代码后马上就把锁还给同步对象,其他在锁池中等待的某个线程就可以拿到锁执行同步代码了。
6.这样就保证了同步代码在统一时刻只有一个线程在执行。
上面提到锁,这里先引出锁的概念。先来看看下面这些啰嗦而必不可少的文字。
多线程的线程同步机制实际上是靠锁的概念来控制的。
在Java程序运行时环境中,JVM需要对两类线程共享的数据进行协调:
1)保存在堆中的实例变量(对象信息放在堆中Heap)
2)保存在方法区中的类变量(类信息放在方法区中Method Area)
这两类数据是被所有线程共享的。
(程序不需要协调保存在Java 栈当中的数据。因为这些数据是属于拥有该栈的线程所私有的。)
方法区(Method Area)与Java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做Non-Heap(非堆),目的应该是与Java堆区分开来。
栈:在Java中,JVM中的栈记录了线程的方法调用。每个线程拥有一个栈。在某个线程的运行过程中,如果有新的方法调用,那么该线程对应的栈就会增加一个存储单元,即帧(frame)。在frame中,保存有该方法调用的参数、局部变量和返回地址。
堆是JVM中一块可自由分配给对象的区域。当我们谈论垃圾回收(garbage collection)时,我们主要回收堆(heap)的空间。
Java的普通对象存活在堆中。与栈不同,堆的空间不会随着方法调用结束而清空。因此,在某个方法中创建的对象,可以在方法调用结束之后,继续存在于堆中。这带来的一个问题是,如果我们不断的创建新的对象,内存空间将最终消耗殆尽。
在java虚拟机中,每个对象和类在逻辑上都是和一个监视器相关联的。
对于对象来说,相关联的监视器保护对象的实例变量。
对于类来说,监视器保护类的类变量。
(如果一个对象没有实例变量,或者一个类没有变量,相关联的监视器就什么也不监视。)
为了实现监视器的排他性监视能力,java虚拟机为每一个对象和类都关联一个锁。代表任何时候只允许一个线程拥有的特权。线程访问实例变量或者类变量不需锁。
但是如果线程获取了锁,那么在它释放这个锁之前,就没有其他线程可以获取同样数据的锁了。(锁住一个对象就是获取对象相关联的监视器)
类锁实际上用对象锁来实现。当虚拟机装载一个class文件的时候,它就会创建一个java.lang.Class类的实例。当锁住一个对象的时候,实际上锁住的是那个类的Class对象。
一个线程可以多次对同一个对象上锁。对于每一个对象,java虚拟机维护一个加锁计数器,线程每获得一次该对象,计数器就加1,每释放一次,计数器就减 1,当计数器值为0时,锁就被完全释放了。
java编程人员不需要自己动手加锁,对象锁是java虚拟机内部使用的。
在java程序中,只需要使用synchronized块或者synchronized方法就可以标志一个监视区域。当每次进入一个监视区域时,java 虚拟机都会自动锁上对象或者类。
参考这篇文章 :https://blog.csdn.net/u013142781/article/details/51697672
在这篇文章中你将会学到如何使用 wait、notify 和 notifyAll 来实现线程间的通信,从而解决生产者消费者问题。如果你想要更深入地学习Java中的多线程同步问题,我强烈推荐阅读Brian Goetz所著的《Java Concurrency in Practice | Java 并发实践》,不读这本书你的 Java 多线程征程就不完整哦!这是我最向Java开发者推荐的书之一。
回到wait(),notify(),notifyAll()这三个方法中来
这里用药店窗口取药的模型可以很好的解释这一点。。。
wait( ),notify( ),notifyAll( )都不属于Thread类,而是属于Object基础类,也就是每个对象都有wait( ),notify( ),notifyAll( ) 的功能,因为每个对象都有锁,锁是每个对象的基础,当然操作锁的方法也是最基础了。
当需要调用以上的方法的时候,一定要对竞争资源进行加锁,如果不加锁的话,则会报 IllegalMonitorStateException 异常
当想要调用wait( )进行线程等待时,必须要取得这个锁对象的控制权(对象监视器),一般是放到synchronized(obj)代码中。
在while循环里而不是if语句下使用wait,这样,会在线程暂停恢复后都检查wait的条件,并在条件实际上并未改变的情况下处理唤醒通知
调用obj.wait( )释放了obj的锁,否则其他线程也无法获得obj的锁,也就无法在synchronized(obj){ obj.notify() } 代码段内唤醒A。
notify( )方法只会通知等待队列中的第一个相关线程(不会通知优先级比较高的线程)
notifyAll( )通知所有等待该竞争资源的线程(也不会按照线程的优先级来执行)
假设有三个线程执行了obj.wait( ),那么obj.notifyAll( )则能全部唤醒tread1,thread2,thread3,但是要继续执行obj.wait()的下一条语句,必须获得obj锁,因此,tread1,thread2,thread3只有一个有机会获得锁继续执行,例如tread1,其余的需要等待thread1释放obj锁之后才能继续执行。
当调用obj.notify/notifyAll后,调用线程依旧持有obj锁,因此,thread1,thread2,thread3虽被唤醒,但是仍无法获得obj锁。直到调用线程退出synchronized块,释放obj锁后,thread1,thread2,thread3中的一个才有机会获得锁继续执行。
wait()与sleep()的区别:
1.首先sleep()是Thread()类的方法,而wait()是Object类的方法,包括notify(),notifyAll()都是Object类的方法
2.sleep()方法是休眠,阻塞线程的同时仍然会持有锁,也就是说它休眠期间其他线程仍然无法获得锁,同时sleep()休眠时自动醒 的;而调用wait()方法时,则自动释放锁,也就是其他线程可以获得锁,而且wait()是无法自动醒的,只有通过notify()或 notifyAll() 才行。如果不设置wait自动醒的时间,那么wait将会一直等下去直至notify来唤醒,进入锁池去获取对象锁。
notify()与notifyAll()的区别
notify()一次只能激活一个对这个对象进行wait()的线程,当多个线程都对此对象wait()时,是随机挑一个notify(),而notifyAll()是一次 性激活所以对此对象进行wait()的线程。
接下来说说利用wait()和notify()来实现生产者和消费者并发问题:
显然要保证生产者和消费者并发运行不出乱,主要要解决:当生产者线程的缓存区为满的时候,就应该调用wait()来停止生产者继续生产,而当生产者满的缓冲区被消费者消费掉一块时,则应该调用notify()唤醒生产者,通知他可以继续生产;同样,对于消费者,当消费者线程的缓存区为空的时候,就应该调用wait()停掉消费者线程继续消费,而当生产者又生产了一个时就应该调用notify()来唤醒消费者线程通知他可以继续消费了。
当然我们必须在wait()和notify()的时候锁住我们所要操作的对象,这里即缓存区,下面是一个使用wait()的notify()的规范代码模板:
synchronized的背景下和那个被多线程共享的对象上调用
synchronized (sharedObject) { //锁住操作对象,锁的是对象
while (condition) { //当某个条件下
sharedObject.wait(); //进入wait,这个shareObject就是所有线程共享的对象,在生产者-消费者模型里面这个对象就是缓冲区队列
}
// 做了什么事,就可以激活,注意在while循环外
shareObject.notify();
}
wait, notify 和 notifyAll,这些在多线程中被经常用到的保留关键字,在实际开发的时候很多时候却并没有被大家重视。本文对这些关键字的使用进行了描述。
在 Java 中可以用 wait、notify 和 notifyAll 来实现线程间的通信。。举个例子,如果你的Java程序中有两个线程——即生产者和消费者,那么生产者可以通知消费者,让消费者开始消耗数据,因为队列缓冲区中有内容待消费(不为空)。相应的,消费者可以通知生产者可以开始生成更多的数据,因为当它消耗掉某些数据后缓冲区不再为满。
我们可以利用wait()来让一个线程在某些条件下暂停运行。例如,在生产者消费者模型中,生产者线程在缓冲区为满的时候,消费者在缓冲区为空的时候,都应该暂停运行。如果某些线程在等待某些条件触发,那当那些条件为真时,你可以用 notify 和 notifyAll 来通知那些等待中的线程重新开始运行。不同之处在于,notify 仅仅通知一个线程,并且我们不知道哪个线程会收到通知,然而 notifyAll 会通知所有等待中的线程。换言之,如果只有一个线程在等待一个信号灯,notify和notifyAll都会通知到这个线程。但如果多个线程在等待这个信号灯,那么notify只会通知到其中一个,而其它线程并不会收到任何通知,而notifyAll会唤醒所有等待中的线程。
如何使用Wait
尽管关于wait和notify的概念很基础,它们也都是Object类的函数,但用它们来写代码却并不简单。如果你在面试中让应聘者来手写代码,用wait和notify解决生产者消费者问题,我几乎可以肯定他们中的大多数都会无所适从或者犯下一些错误,例如在错误的地方使用 synchronized 关键词,没有对正确的对象使用wait,或者没有遵循规范的代码方法。说实话,这个问题对于不常使用它们的程序员来说确实令人感觉比较头疼。
第一个问题就是,我们怎么在代码里使用wait()呢?因为wait()并不是Thread类下的函数,我们并不能使用Thread.call()。事实上很多Java程序员都喜欢这么写,因为它们习惯了使用Thread.sleep(),所以他们会试图使用wait() 来达成相同的目的,但很快他们就会发现这并不能顺利解决问题。正确的方法是对在多线程间共享的那个Object来使用wait。在生产者消费者问题中,这个共享的Object就是那个缓冲区队列。
第二个问题是,既然我们应该在synchronized的函数或是对象里调用wait,那哪个对象应该被synchronized呢?答案是,那个你希望上锁的对象就应该被synchronized,即那个在多个线程间被共享的对象。在生产者消费者问题中,应该被synchronized的就是那个缓冲区队列。(我觉得这里是英文原文有问题……本来那个句末就不应该是问号不然不太通……)
永远在循环(loop)里调用 wait 和 notify,不是在 If 语句,常用的是while循环
现在你知道wait应该永远在被synchronized的背景下和那个被多线程共享的对象上调用,下一个一定要记住的问题就是,你应该永远在while循环,而不是if语句中调用wait。因为线程是在某些条件下等待的——在我们的例子里,即“如果缓冲区队列是满的话,那么生产者线程应该等待”,你可能直觉就会写一个if语句。但if语句存在一些微妙的小问题,导致即使条件没被满足,你的线程你也有可能被错误地唤醒。所以如果你不在线程被唤醒后再次使用while循环检查唤醒条件是否被满足,你的程序就有可能会出错——例如在缓冲区为满的时候生产者继续生成数据,或者缓冲区为空的时候消费者开始消耗数据。所以记住,永远在while循环而不是if语句中使用wait!我会推荐阅读《Effective Java》,这是关于如何正确使用wait和notify的最好的参考资料。
就像我之前说的一样,在while循环里使用wait的目的,是在线程被唤醒的前后都持续检查条件是否被满足。如果条件并未改变,wait被调用之前notify的唤醒通知就来了,那么这个线程并不能保证被唤醒,有可能会导致死锁问题。
下面我们提供一个使用wait和notify的范例程序。在这个程序里,我们使用了上文所述的一些代码规范。
我们有两个线程,分别名为PRODUCER(生产者)和CONSUMER(消费者),他们分别继承了了Producer和Consumer类,而Producer和Consumer都继承了Thread类。Producer和Consumer想要实现的代码逻辑都在run()函数内。
Main线程开始了生产者和消费者线程,并声明了一个LinkedList作为缓冲区队列(在Java中,LinkedList实现了队列的接口)。生产者在无限循环中持续往LinkedList里插入随机整数直到LinkedList满。我们在while(queue.size == maxSize)循环语句中检查这个条件。请注意到我们在做这个检查条件之前已经在队列对象上使用了synchronized关键词,因而其它线程不能在我们检查条件时改变这个队列。如果队列满了,那么PRODUCER线程会在CONSUMER线程消耗掉队列里的任意一个整数,并用notify来通知PRODUCER线程之前持续等待。在我们的例子中,wait和notify都是使用在同一个共享对象上的。
这一套程序如果能在面试中写出来那就给劲了,其实逻辑并不难,只需要按照套路来即可。
import java.util.LinkedList;
import java.util.Queue;
import java.util.Random;
/**
* Simple Java program to demonstrate How to use wait, notify and notifyAll()
* method in Java by solving producer consumer problem.
*
* @author Javin Paul
*/
public class ProducerConsumerInJava {
public static void main(String args[]) {
System.out.println("How to use wait and notify method in Java");
System.out.println("Solving Producer Consumper Problem");
Queue<Integer> buffer = new LinkedList<>();
int maxSize = 10;
Thread producer = new Producer(buffer, maxSize, "PRODUCER");
Thread consumer = new Consumer(buffer, maxSize, "CONSUMER");
producer.start(); consumer.start(); }
}
/**
* Producer Thread will keep producing values for Consumer
* to consumer. It will use wait() method when Queue is full
* and use notify() method to send notification to Consumer
* Thread.
*
* @author WINDOWS 8
*
*/
class Producer extends Thread
{ private Queue<Integer> queue;
private int maxSize;
public Producer(Queue<Integer> queue, int maxSize, String name){
super(name); this.queue = queue; this.maxSize = maxSize;
}
@Override public void run()
{
while (true)
{
synchronized (queue) {
while (queue.size() == maxSize) { //queue满了,那么Producer就要被wait
try {
System.out .println("Queue is full, " + "Producer thread waiting for " + "consumer to take something from queue");
queue.wait();
} catch (Exception ex) {
ex.printStackTrace(); }
}
Random random = new Random();
int i = random.nextInt();
System.out.println("Producing value : " + i);
queue.add(i);
queue.notifyAll();
}
}
}
}
/**
* Consumer Thread will consumer values form shared queue.
* It will also use wait() method to wait if queue is
* empty. It will also use notify method to send
* notification to producer thread after consuming values
* from queue.
*
* @author WINDOWS 8
*
*/
class Consumer extends Thread {
private Queue<Integer> queue;
private int maxSize;
public Consumer(Queue<Integer> queue, int maxSize, String name){
super(name);
this.queue = queue;
this.maxSize = maxSize;
}
@Override public void run() {
while (true) {
synchronized (queue) {
while (queue.isEmpty()) { //queue空的时候,Consumer要被wait
System.out.println("Queue is empty," + "Consumer thread is waiting" + " for producer thread to put something in queue");
try {
queue.wait();
} catch (Exception ex) {
ex.printStackTrace();
}
}
System.out.println("Consuming value : " + queue.remove());
queue.notifyAll();
}
}
}
}
参考资料:http://www.importnew.com/16453.html
如何在 Java 中正确使用 wait, notify 和 notifyAll – 以生产者消费者模型为例
为了更好地理解这个程序,我建议你在debug模式里跑这个程序。一旦你在debug模式下启动程序,它会停止在PRODUCER或者CONSUMER线程上,取决于哪个线程占据了CPU。因为两个线程都有wait()的条件,它们一定会停止,然后你就可以跑这个程序然后看发生什么了(很有可能它就会输出我们以上展示的内容)。你也可以使用Eclipse里的Step into和Step over按钮来更好地理解多线程间发生的事情。
你可以使用wait和notify函数来实现线程间通信。你可以用它们来实现多线程(>3)之间的通信。
永远在synchronized的函数或对象里使用wait、notify和notifyAll,不然Java虚拟机会生成 IllegalMonitorStateException。
永远在while循环里而不是if语句下使用wait。这样,循环会在线程睡眠前后都检查wait的条件,并在条件实际上并未改变的情况下处理唤醒通知。
永远在多线程间共享的对象(在生产者消费者模型里即缓冲区队列)上使用wait。
基于前文提及的理由,更倾向用 notifyAll(),而不是 notify()。
来点新东西吧
在JAVA1.8或1.9中,并发工具的改变
Java 8 中 Concurrent package的改变
java.util.concurrent中新的类和接口
增加了两个新接口和4个新类:
接口 CompletableFuture.AsynchronousCompletionTask
接口 CompletionStage
类 CompletableFuture
类 ConcurrentHashMap.KeySetView
类 CountedCompleter
类 CompletionException
java.util.concurrent.ConcurrentHashMap的新方法
集合框架 在Java 8中做了修订,基于 stream 和 lambda表达式 添加了很多聚合方法。因此 ConcurrentHashMap 也引入了30几个新方法,包括各种 foreach 方法(forEach , forEachKey , forEachValue , 和 forEachEntry )、搜索方法( search , searchKeys , searchValues , 和 searchEntries )和reduction方法( reduce ,reduceToDouble , reduceToLong 等)。
也添加了一些其它方法,比如 mappingCount 和 newKeySet 。并且当前版本的 ConcurrentHashMap 的更适合做cache,因为增加了当键值不存在的时候的检查方法。
java.util.concurrent.atomic中的新类
为了并发计算count、sum, 新引入了 DoubleAccumulator , DoubleAdder , LongAccumulator , LongAdder 类,比Atomic提供更高的吞吐率。
java.util.concurrent.ForkJoinPool的新方法
静态的 commonPool() 新加入,可以为ForkJoinTask提供通用池。
两个方法 getCommonPoolParallelism() 和 commonPool() 提供不同的配置。
新类 java.util.concurrent.locks.StampedLock
新类 StampedLock 提供三种模式(写,读,乐观读),用来提高性能。
Java 9 中 Concurrent package的改变
主要是 JEP 266: More Concurrency Updates , 包括publish-subscribe, CompletableFuture 接口的加强等。
支持Reactive Streams publish-subscribe框架,四个接口 Processor 、 Publisher 、 Subscriber 、 Subscription ,容器类 java.util.concurrent.Flow 、java.util.concurrent.SubmissionPublisher
CompletableFuture类加强,支持delays, timeout, subclassing 以及其它方法
调优以及修改javadoc
普及JAVA内存管理机制
因为线程调度跟内存分配有着很大的关系。
转载内容,觉得这篇是我看过讲得最好的:https://blog.csdn.net/u013142781/article/details/50830754
请注意上图的这个:

我们再来复习下进程与线程吧:
进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
似乎现在更好理解了一些:
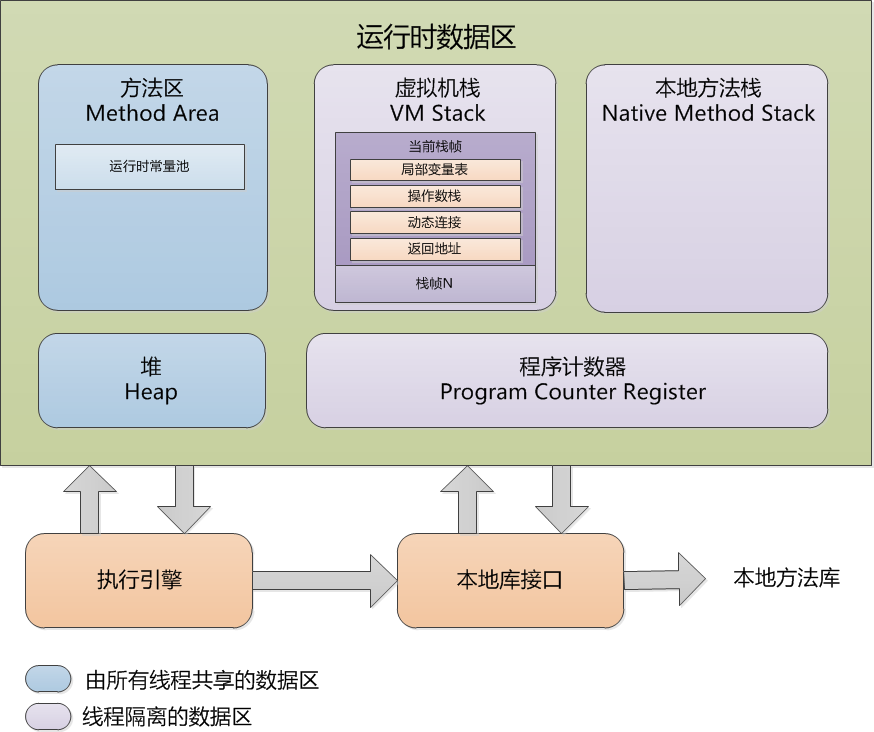
方法区和堆是分配给进程的,也就是所有线程共享的。
而栈和程序计数器,则是分配给每个独立线程的,是运行过程中必不可少的资源。
下面我们逐个看下栈、堆、方法区和程序计数器。
1、方法区(Method Area)
方法区(Method Area)与Java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做Non-Heap(非堆),目的应该是与Java堆区分开来。
2、程序计数器(Program Counter Register)
程序计数器(Program Counter Register)是一块较小的内存空间,它的作用可以看做是当前线程所执行的字节码的行号指示器。在虚拟机的概念模型里(仅是概念模型,各种虚拟机可能会通过一些更高效的方式去实现),字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
下面重点解下Java内存管理中的栈和堆。
3、栈(Stacks)
在Java中,JVM中的栈记录了线程的方法调用。每个线程拥有一个栈。在某个线程的运行过程中,如果有新的方法调用,那么该线程对应的栈就会增加一个存储单元,即帧(frame)。在frame中,保存有该方法调用的参数、局部变量和返回地址。
Java的参数和局部变量只能是基本类型的变量(比如int),或者对象的引用(reference)。因此,在栈中,只保存有基本类型的变量和对象引用。引用所指向的对象保存在堆中。(引用可能为Null值,即不指向任何对象)。
当被调用方法运行结束时,该方法对应的帧将被删除,参数和局部变量所占据的空间也随之释放。线程回到原方法,继续执行。当所有的栈都清空时,程序也随之运行结束。
本地方法栈与虚拟机栈的区别:
本地方法栈(Native Method Stacks)与虚拟机栈所发挥的作用是非常相似的,其区别不过是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的Native方法服务。虚拟机规范中对本地方法栈中的方法使用的语言、使用方式与数据结构并没有强制规定,因此具体的虚拟机可以自由实现它。甚至有的虚拟机(譬如Sun HotSpot虚拟机)直接就把本地方法栈和虚拟机栈合二为一。与虚拟机栈一样,本地方法栈区域也会抛出StackOverflowError和OutOfMemoryError异常。
4、堆(Heap)
堆是JVM中一块可自由分配给对象的区域。当我们谈论垃圾回收(garbage collection)时,我们主要回收堆(heap)的空间。
Java的普通对象存活在堆中。与栈不同,堆的空间不会随着方法调用结束而清空。因此,在某个方法中创建的对象,可以在方法调用结束之后,继续存在于堆中。这带来的一个问题是,如果我们不断的创建新的对象,内存空间将最终消耗殆尽。
垃圾回收(Garbage Collection,GC)
垃圾回收(garbage collection,简称GC)可以自动清空堆中不再使用的对象。垃圾回收机制最早出现于1959年,被用于解决Lisp语言中的问题。垃圾回收是Java的一大特征。并不是所有的语言都有垃圾回收功能。比如在C/C++中,并没有垃圾回收的机制。程序员需要手动释放堆中的内存。
由于不需要手动释放内存,程序员在编程中也可以减少犯错的机会。利用垃圾回收,程序员可以避免一些指针和内存泄露相关的bug(这一类bug通常很隐蔽)。但另一方面,垃圾回收需要耗费更多的计算时间。垃圾回收实际上是将原本属于程序员的责任转移给计算机。使用垃圾回收的程序需要更长的运行时间。
在Java中,对象的是通过引用使用的(把对象相像成致命的毒物,引用就像是用于提取毒物的镊子)。如果不再有引用指向对象,那么我们就再也无从调用或者处理该对象。这样的对象将不可到达(unreachable)。垃圾回收用于释放不可到达对象所占据的内存。这是垃圾回收的基本原则。
早期的垃圾回收采用引用计数(reference counting)的机制。每个对象包含一个计数器。当有新的指向该对象的引用时,计数器加1。当引用移除时,计数器减1。当计数器为0时,认为该对象可以进行垃圾回收。
然而,一个可能的问题是,如果有两个对象循环引用(cyclic reference),比如两个对象互相引用,而且此时没有其它(指向A或者指向B)的引用,我们实际上根本无法通过引用到达这两个对象。
因此,我们以栈和static数据为根(root),从根出发,跟随所有的引用,就可以找到所有的可到达对象。也就是说,一个可到达对象,一定被根引用,或者被其他可到达对象引用。
5、再整理下
通常我们定义一个基本数据类型的变量,一个对象的引用,还有就是函数调用的现场保存都使用内存中的栈空间;
而通过new关键字和构造器创建的对象放在堆空间;
程序中的字面量(literal)如直接书写的100、”hello”和常量都是放在静态区中;
栈空间操作起来最快但是栈很小,通常大量的对象都是放在堆空间,理论上整个内存没有被其他进程使用的空间甚至硬盘上的虚拟内存都可以被当成堆空间来使用。

