Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程。也被称为spring的脚手架。
该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。
spring boot 致力于简洁,让开发者写更少的配置,程序能够更快的运行和启动。它是下一代javaweb框架,并且它是spring cloud(微服务)的基础。(spring cloud的基础就是基于spring boot来进行配置),spring boot就是为了让开发人员从繁重的配置工作解放出来,快速参与开发。
- 创建独立的Spring应用程序
- 嵌入的Tomcat,无需部署WAR文件
- 简化Maven配置
- 自动配置Spring
- 提供生产就绪型功能,如指标,健康检查和外部配置
- 绝对没有代码生成和对XML没有要求配置(由java配置替代XML配置,也就是零XML配置)
从最根本上来讲,Spring Boot就是一些库的集合,它能够被任意项目的构建系统所使用。简便起见,该框架也提供了命令行界面,它可以用来运行和测试Boot应用。框架的发布版本,包括集成的CLI(命令行界面),可以在Spring仓库中手动下载和安装。一种更为简便的方式是使用Groovy环境管理器(Groovy enVironment Manager,GVM),它会处理Boot版本的安装和管理。Boot及其CLI可以通过GVM的命令行gvm install springboot进行安装。
要进行打包和分发的工程会依赖于像Maven或Gradle这样的构建系统。为了简化依赖图,Boot的功能是模块化的,通过导入Boot所谓的“starter”模块,可以将许多的依赖添加到工程之中。为了更容易地管理依赖版本和使用默认配置,框架提供了一个parent POM,工程可以继承它。
如何spring boot快速开发
如何进行spring boot的快速开发和学习,以便于熟悉这个框架所带来的方便。
最好的办法就是在项目中去参与开发,体验会所带来的FEEL!!
首先我们需要一个项目以方便我们了解利用spirng boot框架的项目里面到底有什么?
Test项目下载
spring官网为我们提供了可方便快速上手体验的Test项目
http://start.spring.io/
在里面根据自己的选择JDK的版本,项目名和包名等等,点击下方的Switch to the full version可以选择java的版本(还可以引入所依赖的组件,这里我们先下载默认的项目,若是以后有需要的jar包再通过maven导入即可)
我的选择界面如下:
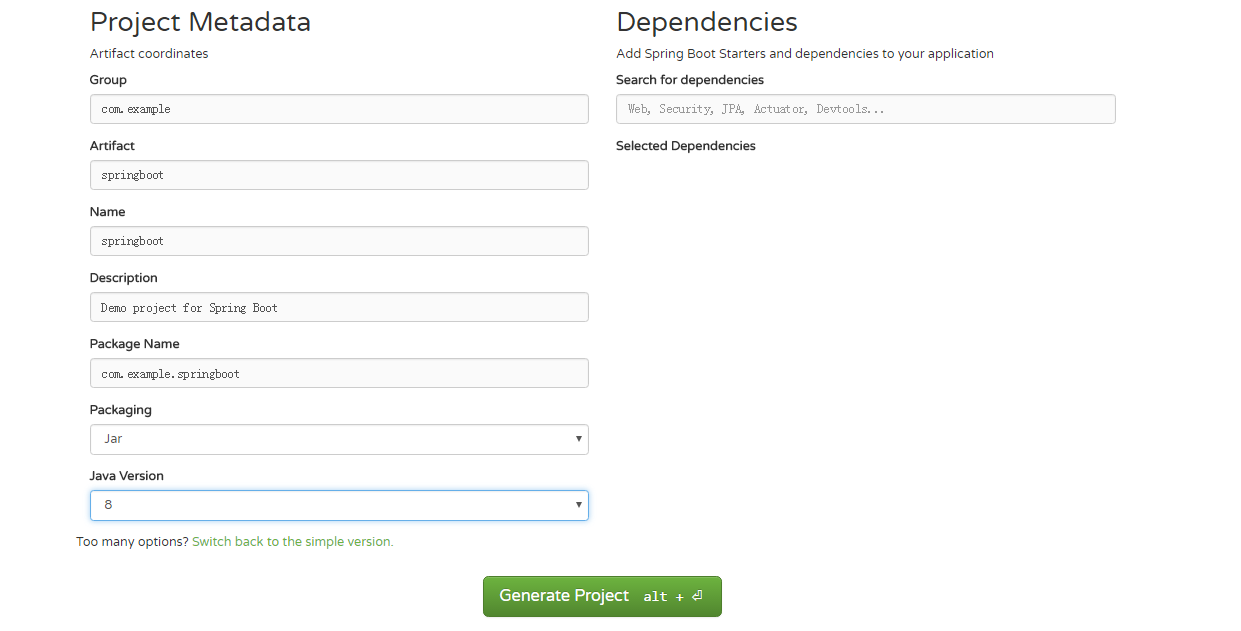
选择好后然后点击Generate Project下载项目压缩包
解压后,使用eclipse,Import -> Existing Maven Projects -> Next ->选择解压后的文件夹-> Finsh,OK done!
项目目录结构分析
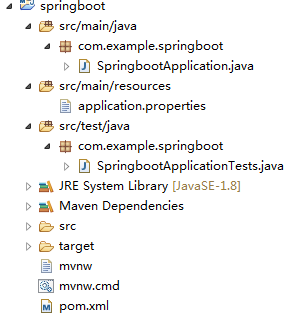
可以看到Spring Boot的基础结构共三个文件
src/main/java 程序开发以及主程序入口
src/main/resources 配置文件
src/test/java 测试程序
这里跟我们平时在eclipse中建立的maven项目目录结构一致
spingboot建议的目录结果如下(根据你的公司的开发格式要求为重):
root package结构:com.example.myproject
com
+- example
+- myproject
+- Application.java
|
+- domain
| +- Customer.java
| +- CustomerRepository.java
|
+- service
| +- CustomerService.java
|
+- controller
| +- CustomerController.java
|
其实也就是分包,按照以往的springmvc的开发模式,Entity中方实体类,也就是数据库与服务端的字段映射POJO,Controller中放控制层(负责页面访问控制),Service中负责处理相关业务逻辑,Dao层负责处理数据库交互,Util负责放入一些工具类,aspect为切面组件,converter为消息转化组件等等。
而spring boot中建议以java配置取代繁重的XML配置(或者用更简化的Groovy来代替),这个项目用java配置演示。
1、Application.java 建议放到跟目录下面,主要用于做一些框架配置(java配置文件)
2、domain 目录主要用于实体(Entity)与数据访问层(Repository)
3、service 层主要是业务类代码
4、controller 负责页面访问控制
采用默认配置可以省去很多配置,当然也可以根据自己的喜欢来进行更改
最后,启动Application main方法,至此一个java项目搭建好了!
项目POM.XML
在项目的POM.xml文件中引入父POM,来初始化一些常用的功能(不用重新去导入其他包,当然也有办法不用这个父POM),项目自动配好了,若是自己编写项目则需要手动配置。
<!-- Inherit defaults from Spring Boot -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.5.2.RELEASE</version>
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<!-- spring-boot-maven-plugin插件 在SpringBoot项目中开启的方式有两种
一种是run java.application 还有一种就是这个插件开启-->
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
<!--支持springboot所需的jar包依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
以上这些就是官网提供项目的POM配置。
还需要引入一个web模块
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
pom.xml文件中默认有两个模块:
spring-boot-starter:核心模块,包括自动配置支持、日志和YAML;
spring-boot-starter-test:测试模块,包括JUnit、Hamcrest、Mockito。
测试一下页面访问的Controller看看效果
package com.example.springboot.controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
//springboot特有注解,包含@Controller和@ResponseBody
//所以这里就相当于控制层组件和输出Json格式字符串,极其方便
@RestController
public class HelloController {
@RequestMapping("/hel")
public String index(){
return "Hello World";
}
//测试成功!
}
注意:本机的tomcat端口若是自己设置的,需要在application.properties中去设置端口号,否则将访问不到。
我的设置是:server.port=8088
配置完后直接测试 http://localhost:8088/hel
出现结果

@RestController的意思就是controller里面的方法都以json格式输出,不用再写什么jackjson配置的了!
跟我们之前所使用的@ResponseBody一样,向浏览器直接输出Json格式的数据
当然在这里我贴出一些可能出现问题的解法包括我自己是怎么解决的
出现的问题及解决方案
当我们部署完后可以直接run运行这个Test项目看下是否输入路径能否得到这个json字符串
这时候可能会出现Whitelabel Error Page的提示,这时候表示这个项目并没运行成功
我去网上找找方法,常见的解决方法是去看看SpringbootApplication.java这个类是否放在项目根目录下(目录结构不对的问题)
因为springboot是默认加载这个配置文件下的所有子包,我查看了一下我的包结构
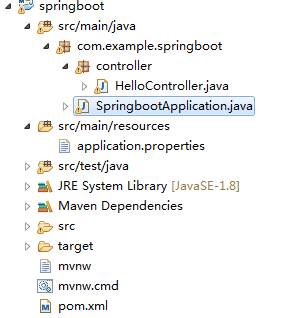
发现并没有问题,SpringbootApplication.java配置也放在根目录下了,controller是其子包没错。
后来发现是springboot项目在运行的时候,eclipse需要你去手动配置springboot的项目以及执行配置的main方法所在类
这时候我们可以在所运行的项目下右键–>run Configuations,然后在Main标签上的project中选择你所要执行的springboot项目
Main Class位置选择执行配置的main方法所在类,这时候重新运行就生效了,这是因为我之前也有用过springboot框架建了一个项目,这时候以为内原来的配置是上一个项目的,这时候需要我们手动去将项目重新设置。
另外这是我的解决方法,每个人都可能遇到不同的问题,所以这就是需要我们要去融入问题本身,再加上eclipse的debug模式去发现系统报给我们的错误的真正原因。
如何做单元测试
利用我们刚刚做的这个Test类,我们要做个单元测试,将服务端和浏览器的交互数据都给打印出来,包括Springmvc各组件的数据交互。
打开的src/test/下的测试入口,编写简单的http请求来测试;使用mockmvc进行,利用MockMvcResultHandlers.print()打印出执行结果。
注意:@SpringApplicationConfiguration(classes = Application.class) 报错,注解不能导入。
//springJunit支持,由于引入了Spring-Test框架支持。
@RunWith(SpringJUnit4ClassRunner.class)
//这个注解在1.5版本后移除了,所以用两个注解就可以实现测试,
//@SpringApplicationConfiguration(classes = MockServletContext.class)
//由于是web项目,Junit需要模拟ServletContext,需要给测试类加上@WebAppConfiguration注解
@WebAppConfiguration
public class HelloWorldControlerTests {
private MockMvc mvc;
@Before
public void setUp() throws Exception {
mvc = MockMvcBuilders.standaloneSetup(new HelloController()).build();
}
@Test
public void getHello() throws Exception {
mvc.perform(MockMvcRequestBuilders.get("/hel").accept(MediaType.APPLICATION_JSON))
.andExpect(MockMvcResultMatchers.status().isOk())
.andDo(MockMvcResultHandlers.print())
.andReturn();
}
}
热启动在正常开发项目中已经很常见了吧,虽然平时开发web项目过程中,改动项目启重启总是报错;但springBoot对调试支持很好,修改之后可以实时生效,需要添加以下的配置:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<fork>true</fork>
</configuration>
</plugin>
</plugins>
</build>
该模块在完整的打包环境下运行的时候会被禁用。如果你使用java -jar启动应用或者用一个特定的classloader启动,它会认为这是一个“生产环境”。
关于Eclipse的热启动及热部署
Tomcat的热部署(以后就不用重启了)
1、 tomcat上的部署问题,有时候也是个麻烦的问题,要是不采用热部署,我们就只能每次对原来的文件做一次改动的时候就要重新部署,
而每次重新部署都要关闭tomcat,部署完重起tomcat,可见这是一个多么烦人的事情。现在,我们可以采用热部署了,以后,就不用做凡人的关闭重起工作。
实现方式:
编辑Tomcat的server.xml
在host节点内加入
“myapp” 为要部署的应用程序,通常在webapps目录下
docBase:指定Web应用的文件路径,可以给定绝对路径,也可以给定相对于
如果Web应用采用开放目录结构,则指定Web应用的根目录,如果Web应用是个war文件,则指定war文件的路径。
reloadable:如果这个属性设为true,tomcat服务器在运行状态下会监视在WEB-INF/classes和WEB-INF/lib目录下class文件的改动,
如果监测到有class文件被更新的,服务器会自动重新加载Web应用。 在开发阶段将reloadable属性设为true,
有助于调试servlet和其它的class文件,但这样用加重服务器运行负荷,建议在Web应用的发存阶段将reloadable设为false。
2、双击tomcat 服务器,切换到modules 界面,把项目的auto_reload 设置为Disabled 保存
这种方法只适用于改变类的方法实现,如果当一个类改变结构、或者配置文件修改了,tomcat是没办法热加载的,需要重启tomcat。
搞定!
使用spring boot可以非常方便、快速搭建项目,使我们不用关心框架之间的兼容性,适用版本等各种问题,我们想使用任何东西,仅仅添加一个配置就可以,所以使用sping boot非常适合构建微服务。
——————更新线——————
关于SpringBootApplication的各项注解配置
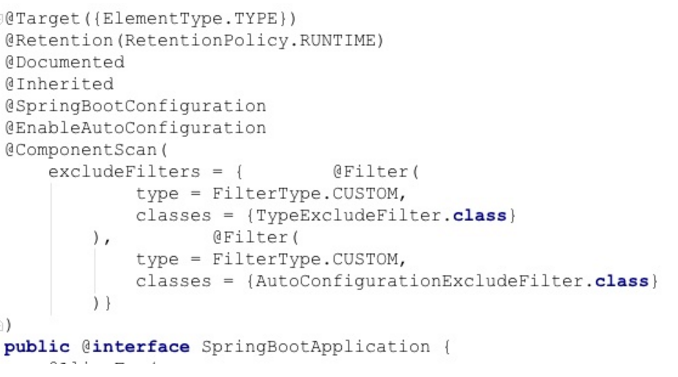
较为常用的注解有以下这些:
@SpringBootApplication:
包含@Configuration、@EnableAutoConfiguration、@ComponentScan
通常用在主类上。
@Repository:
用于标注数据访问组件,即DAO组件。
@Service:
用于标注业务层组件。
@RestController:
4.0重要的一个新的改进是@RestController注解,它继承自@Controller注解。4.0之前的版本,Spring MVC的组件都使用@Controller来标识当前类是一个控制器servlet。使用这个特性,我们可以开发REST服务的时候不需要使用@Controller而专门的@RestController。
当你实现一个RESTful web services的时候,response将一直通过response body发送。为了简化开发,Spring 4.0提供了一个专门版本的controller。
用于标注控制层组件(如struts中的action),包含@Controller和@ResponseBody。
@ResponseBody:
表示该方法的返回结果直接写入HTTP response body中
一般在异步获取数据时使用,在使用@RequestMapping后,返回值通常解析为跳转路径,加上@responsebody后返回结果不会被解析为跳转路径,而是直接写入HTTP response body中。比如异步获取json数据,加上@responsebody后,会直接返回json数据。
@Controller
如果我们需要使用页面开发只要使用 @Controller
@Component:
泛指组件,当组件不好归类的时候,我们可以使用这个注解进行标注。
@ComponentScan:
组件扫描。个人理解相当于context:component-scan,如果扫描到有@Component @Controller @Service等这些注解的类,则把这些类注册为bean。
@Configuration:
指出该类是 Bean 配置的信息源,相当于XML中的
@Bean:
相当于XML中的
@EnableAutoConfiguration:
让 Spring Boot 根据应用所声明的依赖来对 Spring 框架进行自动配置,一般加在主类上。
@AutoWired:
byType方式。把配置好的Bean拿来用,完成属性、方法的组装,它可以对类成员变量、方法及构造函数进行标注,完成自动装配的工作。
当加上(required=false)时,就算找不到bean也不报错。
@Qualifier:
当有多个同一类型的Bean时,可以用@Qualifier(“name”)来指定。与@Autowired配合使用
@Resource(name=”name”,type=”type”):
没有括号内内容的话,默认byName。与@Autowired干类似的事。
@RequestMapping:
RequestMapping是一个用来处理请求地址映射的注解,可用于类或方法上。用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径。
该注解有六个属性:
params:指定request中必须包含某些参数值是,才让该方法处理。
headers:指定request中必须包含某些指定的header值,才能让该方法处理请求。
value:指定请求的实际地址,指定的地址可以是URI Template 模式
method:指定请求的method类型, GET、POST、PUT、DELETE等
consumes:指定处理请求的提交内容类型(Content-Type),如application/json,text/html;
produces:指定返回的内容类型,仅当request请求头中的(Accept)类型中包含该指定类型才返回
@RequestParam:
用在方法的参数前面。可以有效规避浏览器传参与服务端属性名字不一致的问题,最好每个参数前面都要加
@RequestParam String a =request.getParameter(“a”)。
@PathVariable:
路径变量。参数与大括号里的名字一样要相同。
RequestMapping("user/get/mac/{macAddress}")
public String getByMacAddress(@PathVariable String macAddress){
//do something;
}
@Profiles
Spring Profiles提供了一种隔离应用程序配置的方式,并让这些配置只能在特定的环境下生效。
任何@Component或@Configuration都能被@Profile标记,从而限制加载它的时机。
@Configuration
@Profile("prod")
public class ProductionConfiguration {
// ...
}
@ConfigurationProperties
Spring Boot将尝试校验外部的配置,默认使用JSR-303(如果在classpath路径中)。
你可以轻松的为你的@ConfigurationProperties类添加JSR-303 javax.validation约束注解:
@Component
@ConfigurationProperties(prefix="connection")
public class ConnectionSettings {
@NotNull
private InetAddress remoteAddress;
// ... getters and setters
}
全局异常处理
@ControllerAdvice:
包含@Component。可以被扫描到。
统一处理异常。
@ExceptionHandler(Exception.class):
用在方法上面表示遇到这个异常就执行以下方法。
自定义Filter
我们常常在项目中会使用filters用于录调用日志、排除有XSS威胁的字符、执行权限验证等等。Spring Boot自动添加了OrderedCharacterEncodingFilter和HiddenHttpMethodFilter,并且我们可以自定义Filter。
两个步骤:
1.实现Filter接口,实现Filter方法
2.添加@Configuration 注解,将自定义Filter加入过滤链
@Configuration
public class WebConfiguration {
@Bean
public RemoteIpFilter remoteIpFilter() {
return new RemoteIpFilter();
}
@Bean
public FilterRegistrationBean testFilterRegistration() {
FilterRegistrationBean registration = new FilterRegistrationBean();
registration.setFilter(new MyFilter());
registration.addUrlPatterns("/*");
registration.addInitParameter("paramName", "paramValue");
registration.setName("MyFilter");
registration.setOrder(1);
return registration;
}
public class MyFilter implements Filter {
@Override
public void destroy() {
// TODO Auto-generated method stub
}
@Override
public void doFilter(ServletRequest srequest, ServletResponse sresponse, FilterChain filterChain)
throws IOException, ServletException {
// TODO Auto-generated method stub
HttpServletRequest request = (HttpServletRequest) srequest;
System.out.println("this is MyFilter,url :"+request.getRequestURI());
filterChain.doFilter(srequest, sresponse);
}
@Override
public void init(FilterConfig arg0) throws ServletException {
// TODO Auto-generated method stub
}
}
}
自定义Property
相信很多人选择Spring Boot主要是考虑到它既能兼顾Spring的强大功能,还能实现快速开发的便捷。我们在Spring Boot使用过程中,最直观的感受就是没有了原来自己整合Spring应用时繁多的XML配置内容,替代它的是在pom.xml中引入模块化的Starter POMs,其中各个模块都有自己的默认配置,所以如果不是特殊应用场景,就只需要在application.properties中完成一些属性配置就能开启各模块的应用。
在web开发的过程中,我经常需要自定义一些配置文件,如何使用呢?让我们来体会参数配置文件的强大!!
-自定义普通参数
配置在application.properties中,例如:
com.neo.title=路飞
com.neo.description=海贼王
@Component
//配置好后,直接在类中用SPEL表达式引用即可,所有的参数配置都是写在这里,都是为了避免将程序写死
public class NeoProperties {
@Value("${com.neo.title}")
private String title;
@Value("${com.neo.description}")
private String description;
//省略getter settet方法
}
-参数间引用
另外,在application.properties中,各参数也可以通过SPEL表达式来调用彼此(参数间引用),比如:
com.neo.title=路飞
com.neo.description=海贼王
com.neo.onepiece=${com.neo.title}是${com.neo.description}
-使用随机数
在一些情况下,有些参数我们需要希望它不是一个固定的值,比如密钥、服务端口等。Spring Boot的属性配置文件中可以通过${random}来产生int值、long值或者string字符串,来支持属性的随机值。
// 随机字符串
com.didispace.blog.value=${random.value}
// 随机int
com.didispace.blog.number=${random.int}
// 随机long
com.didispace.blog.bignumber=${random.long}
// 10以内的随机数
com.didispace.blog.test1=${random.int(10)}
// 10-20的随机数
com.didispace.blog.test2=${random.int[10,20]}
-通过命令行设置属性值
不仅可以通过applecation.properties文件来配置参数,还可以用命令行的方式
相信使用过一段时间Spring Boot的用户,一定知道这条命令:java -jar xxx.jar –server.port=8888,通过使用–server.port属性来设置xxx.jar应用的端口为8888。
在命令行运行时,连续的两个减号–就是对application.properties中的属性值进行赋值的标识。所以,java -jar xxx.jar –server.port=8888命令,等价于我们在application.properties中添加属性server.port=8888,该设置在样例工程中可见,读者可通过删除该值或使用命令行来设置该值来验证。
通过命令行来修改属性值固然提供了不错的便利性,但是通过命令行就能更改应用运行的参数,那岂不是很不安全?是的,所以Spring Boot也贴心的提供了屏蔽命令行访问属性的设置,只需要这句设置就能屏蔽:SpringApplication.setAddCommandLineProperties(false)。
log配置
配置输出的地址和输出级别,同样也是在application.properties里面设置参数即可
logging.path=/user/local/log
logging.level.com.favorites=DEBUG
logging.level.org.springframework.web=INFO
logging.level.org.hibernate=ERROR
path为本机的log地址,logging.level 后面可以根据包路径配置不同资源的log级别(关于等级说明在java常用类库–log日志 里面可以找到)
将日志输出到指定位置
数据库操作
重点讲述mysql、spring data jpa的使用,其中mysql 就不用说了大家很熟悉,jpa是利用Hibernate生成各种自动化的sql,如果只是简单的增删改查,基本上不用手写了,spring内部已经帮大家封装实现了。
实现了Mysql与Hibernate的结合,既可以自动生成sql语句简化开发,又可以利用mysql的快速方便不冗余的特点。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
数据库及jpa配置文件(写在application.properties里)
spring.datasource.url=jdbc:mysql://localhost:3306/test
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.jpa.properties.hibernate.hbm2ddl.auto=update
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL5InnoDBDialect
spring.jpa.show-sql= true
其实这个hibernate.hbm2ddl.auto参数的作用主要用于:自动创建|更新|验证数据库表结构,有四个值:
1.create: 每次加载hibernate时都会删除上一次的生成的表,然后根据你的model类再重新来生成新表,哪怕两次没有任何改变也要这样执行,这就是导致数据库表数据丢失的一个重要原因。
2.create-drop :每次加载hibernate时根据model类生成表,但是sessionFactory一关闭,表就自动删除。
3.update:最常用的属性,第一次加载hibernate时根据model类会自动建立起表的结构(前提是先建立好数据库),以后加载hibernate时根据 model类自动更新表结构,即使表结构改变了但表中的行仍然存在不会删除以前的行。要注意的是当部署到服务器后,表结构是不会被马上建立起来的,是要等 应用第一次运行起来后才会。
4.validate :每次加载hibernate时,验证创建数据库表结构,只会和数据库中的表进行比较,不会创建新表,但是会插入新值。
dialect 主要是指定生成表名的存储引擎为InneoDB
show-sql 是否打印出自动生产的SQL,方便调试的时候查看
添加实体类和Dao:
@Entity
public class User implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue
private Long id;
@Column(nullable = false, unique = true)
private String userName;
@Column(nullable = false)
private String passWord;
@Column(nullable = false, unique = true)
private String email;
@Column(nullable = true, unique = true)
private String nickName;
@Column(nullable = false)
private String regTime;
//省略getter settet方法、构造方法
}
关于@Column 注解详情
@Column标记表示所持久化属性所映射表中的字段,该注释的属性定义如下:
@Target({METHOD, FIELD}) @Retention(RUNTIME)
public @interface Column {
String name() default "";
boolean unique() default false;
boolean nullable() default true;
boolean insertable() default true;
boolean updatable() default true;
String columnDefinition() default "";
String table() default "";
int length() default 255;
int precision() default 0;
int scale() default 0;
}
在使用此@Column标记时,需要注意以下几个问题:
此标记可以标注在getter方法或属性前,例如以下的两种标注方法都是正确的:
标注在属性前:
@Entity
@Table(name = "contact")
public class ContactEO{
@Column(name=" contact_name ")
private String name;
}
标注在getter方法前:
@Entity
@Table(name = "contact")
public class ContactEO{
@Column(name=" contact_name ")
public String getName() {
return name;
}
}
JPA规范中并没有明确指定那种标注方法,只要两种标注方式任选其一都可以。这根据个人的喜好来选择
属性都是什么意思:
unique属性表示该字段是否为唯一标识,默认为false。如果表中有一个字段需要唯一标识,则既可以使用该标记,也可以使用@Table标记中的@UniqueConstraint。
nullable属性表示该字段是否可以为null值,默认为true。
insertable属性表示在使用“INSERT”脚本插入数据时,是否需要插入该字段的值。
updatable属性表示在使用“UPDATE”脚本插入数据时,是否需要更新该字段的值。insertable和updatable属性一般多用于只读的属性,例如主键和外键等。这些字段的值通常是自动生成的。
columnDefinition属性表示创建表时,该字段创建的SQL语句,一般用于通过Entity生成表定义时使用。
table属性表示当映射多个表时,指定表的表中的字段。默认值为主表的表名。有关多个表的映射将在本章的5.6小节中详细讲述。
length属性表示字段的长度,当字段的类型为varchar时,该属性才有效,默认为255个字符。
precision属性和scale属性表示精度,当字段类型为double时,precision表示数值的总长度,scale表示小数点所占的位数。
dao只要继承JpaRepository类就可以,几乎可以不用写方法,还有一个特别有尿性的功能非常赞,就是可以根据方法名来自动的生产SQL,比如findByUserName 会自动生产一个以 userName 为参数的查询方法,比如 findAlll 自动会查询表里面的所有数据,比如自动分页等等
Entity中不映射成列的字段得加@Transient 注解,不加注解也会映射成列
package com.example.springboot.domain;
import org.springframework.data.jpa.repository.JpaRepository;
public interface UserDao extends JpaRepository<User, Long>{
User findByUserName(String userName);
User findByUserNameOrEmail(String username, String email);
}
测试:
@RunWith(SpringJUnit4ClassRunner.class)
//@SpringApplicationConfiguration(Application.class)
public class UserDaoTest {
@Autowired
private UserDao userDao;
@Test
public void test() throws Exception {
Date date = new Date();
DateFormat dateFormat = DateFormat.getDateTimeInstance(DateFormat.LONG, DateFormat.LONG);
String formattedDate = dateFormat.format(date);
userDao.save(new User("1","aaa","123456","123@com","AAA",formattedDate));
userDao.save(new User("2","bbb","123456","123@com","BBB",formattedDate));
userDao.save(new User("3","ccc","123456","123@com","CCC",formattedDate));
Assert.assertEquals(9, userDao.findAll().size());
Assert.assertEquals("bb", userDao.findByUserNameOrEmail("bbb", "123@com").getNickName());
userDao.delete(userDao.findByUserName("aaa"));
}
}
thymeleaf模板
Spring boot 推荐使用来代替jsp
Thymeleaf是一款用于渲染XML/XHTML/HTML5内容的模板引擎。类似JSP,Velocity,FreeMaker等,它也可以轻易的与Spring MVC等Web框架进行集成作为Web应用的模板引擎。与其它模板引擎相比,Thymeleaf最大的特点是能够直接在浏览器中打开并正确显示模板页面,而不需要启动整个Web应用。
1.Thymeleaf 在有网络和无网络的环境下皆可运行,即它可以让美工在浏览器查看页面的静态效果,也可以让程序员在服务器查看带数据的动态页面效果。这是由于它支持 html 原型,然后在 html 标签里增加额外的属性来达到模板+数据的展示方式。浏览器解释 html 时会忽略未定义的标签属性,所以 thymeleaf 的模板可以静态地运行;当有数据返回到页面时,Thymeleaf 标签会动态地替换掉静态内容,使页面动态显示。
2.Thymeleaf 开箱即用的特性。它提供标准和spring标准两种方言,可以直接套用模板实现JSTL、 OGNL表达式效果,避免每天套模板、该jstl、改标签的困扰。同时开发人员也可以扩展和创建自定义的方言。
3.Thymeleaf 提供spring标准方言和一个与 SpringMVC 完美集成的可选模块,可以快速的实现表单绑定、属性编辑器、国际化等功能。
我们已经习惯使用了什么 velocity,FreMaker,beetle之类的模版,那么到底好在哪里呢? 比一比吧 Thymeleaf是与众不同的,因为它使用了自然的模板技术。这意味着Thymeleaf的模板语法并不会破坏文档的结构,模板依旧是有效的XML文档。模板还可以用作工作原型,Thymeleaf会在运行期替换掉静态值。Velocity与FreeMarker则是连续的文本处理器。 下面的代码示例分别使用Velocity、FreeMarker与Thymeleaf打印出一条消息:
Velocity: <p>$message</p>
FreeMarker: <p>${message}</p>
Thymeleaf: <p th:text="${message}">Hello World!</p>
注意:由于Thymeleaf使用了XML DOM解析器,因此它并不适合于处理大规模的XML文件。
具体的在组件官方网站有详细介绍:https://www.thymeleaf.org/doc/tutorials/3.0/usingthymeleaf.html#introducing-thymeleaf
涵盖了常见的前端操作,比如,判断,循环,引入模板,常用函数(日期格式化,字符串操作)下拉,js和css中使用,基本可以应对一般场景。
引用命名空间
在html中引入此命名空间,可避免编辑器出现html验证错误,虽然加不加命名空间对Thymeleaf的功能没有任何影响。
- URL
URL在Web应用模板中占据着十分重要的地位,需要特别注意的是Thymeleaf对于URL的处理是通过语法@{…}来处理的。Thymeleaf支持绝对路径URL:
<a th:href="@{http://www.thymeleaf.org}">Thymeleaf</a>
- 条件求值
等等,在开发文档中都有介绍
- 页面即原型
在Web开发过程中一个绕不开的话题就是前端工程师与后端工程师的写作,在传统Java Web开发过程中,前端工程师和后端工程师一样,也需要安装一套完整的开发环境,然后各类Java IDE中修改模板、静态资源文件,启动/重启/重新加载应用服务器,刷新页面查看最终效果。
但实际上前端工程师的职责更多应该关注于页面本身而非后端,使用JSP,Velocity等传统的Java模板引擎很难做到这一点,因为它们必须在应用服务器中渲染完成后才能在浏览器中看到结果,而Thymeleaf从根本上颠覆了这一过程,通过属性进行模板渲染不会引入任何新的浏览器不能识别的标签。
Thymeleaf的用法也可参考:https://www.cnblogs.com/topwill/p/7434955.html
WebJars
WebJars是一个很神奇的东西,可以让大家以jar包的形式来使用前端的各种框架、组件。
什么是WebJars?WebJars是将客户端(浏览器)资源(JavaScript,Css等)打成jar包文件,以对资源进行统一依赖管理。WebJars的jar包部署在Maven中央仓库上。
我们在开发Java web项目的时候会使用像Maven,Gradle等构建工具以实现对jar包版本依赖管理,以及项目的自动化管理,但是对于JavaScript,Css等前端资源包,我们只能采用拷贝到webapp下的方式,这样做就无法对这些资源进行依赖管理。那么WebJars就提供给我们这些前端资源的jar包形势,我们就可以进行依赖管理。
WebJars官网:http://www.webjars.org/
WebJars教程整理:https://www.cnblogs.com/liaojie970/p/7852576.html
关于SpringBoot的多环境配置(实际开发)
我们在开发Spring Boot应用时,通常同一套程序会被应用和安装到几个不同的环境,比如:开发、测试、生产等。其中每个环境的数据库地址、服务器端口等等配置都会不同,如果在为不同环境打包时都要频繁修改配置文件的话,那必将是个非常繁琐且容易发生错误的事。
对于多环境的配置,各种项目构建工具或是框架的基本思路是一致的,通过配置多份不同环境的配置文件,再通过打包命令指定需要打包的内容之后进行区分打包,Spring Boot也不例外,或者说更加简单。
1、开发环境是指开发时所运行的环境,比较随意,只是为了方便开发调试的,是对程序员开放的;
而生产环境就不一样了,
2、生产环境是系统开发的最后一个环节了,也就是上线,是要提供对外服务的,是要关闭错误报告的,然后把日志打印出来;
还有一个测试环境对吧,那就顾名思义,
3、测试环境就是上线前的测试,测试环境都不通过的话,肯定是不能上线的啊,也就是不能发布到生产环境上。
系统开发流程及对应环境:
开发(开发环境,随意,重运行)—>测试(测试环境,重功能)—>上线(生产环境,重实现)
在Spring Boot中多环境配置文件名需要满足application-{profile}.properties的格式,其中{profile}对应你的环境标识,比如:
application-dev.properties:开发环境
application-test.properties:测试环境
application-prod.properties:生产环境
至于哪个具体的配置文件会被加载,需要在application.properties文件中通过spring.profiles.active属性来设置,其值对应{profile}值。
如:spring.profiles.active=test就会加载application-test.properties配置文件内容
下面,以不同环境配置不同的服务端口为例,进行样例实验。
针对各环境新建不同的配置文件application-dev.properties、application-test.properties、application-prod.properties
在这三个文件均都设置不同的server.port属性,如:dev环境设置为1111,test环境设置为2222,prod环境设置为3333
application.properties中设置spring.profiles.active=dev,就是说默认以dev环境设置
测试不同配置的加载
执行java -jar xxx.jar,可以观察到服务端口被设置为1111,也就是默认的开发环境(dev)
执行java -jar xxx.jar –spring.profiles.active=test,可以观察到服务端口被设置为2222,也就是测试环境的配置(test)
执行java -jar xxx.jar –spring.profiles.active=prod,可以观察到服务端口被设置为3333,也就是生产环境的配置(prod)
按照上面的实验,可以如下总结多环境的配置思路:
application.properties中配置通用内容,并设置spring.profiles.active=dev,以开发环境为默认配置
application-{profile}.properties中配置各个环境不同的内容
通过命令行方式去激活不同环境的配置
关于springboot的AOP
AOP即aspect oriented programming面向切面编程,不需要修改原本代码便可将独立功能切入某个层面。通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术。AOP是Spring框架中的一个重要内容,它通过对既有程序定义一个切入点,然后在其前后切入不同的执行内容,比如常见的有:打开数据库连接/关闭数据库连接、打开事务/关闭事务、记录日志等。基于AOP不会破坏原来程序逻辑,因此它可以很好的对业务逻辑的各个部分进行隔离,从而使得业务逻辑各部分之间的耦合度降低,提高程序的可重用性,同时提高了开发的效率。
aop的理解:我们传统的编程方式是垂直化的编程,即A–>B–>C–>D这么下去,一个逻辑完毕之后执行另外一段逻辑。但是AOP提供了另外一种思路,它的作用是在业务逻辑不知情(即业务逻辑不需要做任何的改动)的情况下对业务代码的功能进行增强,这种编程思想的使用场景有很多,例如事务提交、方法执行之前的权限检测、日志打印、方法调用事件等等
其用到的动态代理技术为:本身集成的JDK动态代理和第三方cglib动态代理
两者本身各有优缺(不过JDK的原理要满足sun规范,cglib就没有那么多的限制)
JDK基于java反射机制,而cglib则是基于asm(java字节码)来动态增加既有类功能的
JDK是在生成切面上足够高效,而cglib则是在生成切面后的功能上比较高效,根据实际需求去选择使用哪种动态代理技术。
AOP在实际开发中能做到很多事,比如在原框架上新追加的切面功能实现,流量审计,WEB日志等等。。
下面主要讲两个内容,一个是如何在Spring Boot中引入Aop功能,二是如何使用Aop做切面去统一处理Web请求的日志。
第一步:确保自己的springboot所属工程存在spring-boot-starter-web模块,导入jar包即可
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
第二步:引入AOP依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
在完成了引入AOP依赖包后,一般来说并不需要去做其他配置。也许在Spring中使用过注解配置方式的人会问是否需要在程序主类中增加@EnableAspectJAutoProxy来启用,实际并不需要。
可以看下面关于AOP的默认配置属性,其中spring.aop.auto属性默认是开启的,也就是说只要引入了AOP依赖后,默认已经增加了@EnableAspectJAutoProxy。
第三步:在applicaton.properties文件中配置AOP的各项属性配置
spring.aop.auto=true //就相当于在在驱动主类上配置了@EnableAspectAutoProxy注解,切面自动代理
spring.aop.proxy-target-class=false //若是不用JDK自动代理,也可以通过这个开启Cglib的自动代理
而当我们需要使用CGLIB来实现AOP的时候,需要配置spring.aop.proxy-target-class=true,不然默认使用的是标准Java的实现。
第四步:确认切点位置
假设切点为:com.didispace.controller包下的控制器,我们需要以这个切点为基础
@RestController
public class HelloController {
@RequestMapping("/hello")
public String hello(@RequestParam String name){
return "HelloKoro";
}
}
第五步:可以编写切面了,自由度超高,基本可以在任何想要的层级上切入逻辑
实现AOP的切面主要有以下几个要素:(主要是切面和切点)
使用@Aspect注解将一个java类定义为切面类
使用@Pointcut定义一个切入点,可以是一个规则表达式,比如下例中某个package下的所有函数,也可以是一个注解等。
根据需要在切入点不同位置的切入内容
-使用@Before在切入点开始处切入内容
-使用@After在切入点结尾处切入内容
-使用@AfterReturning在切入点return内容之后切入内容(可以用来对处理返回值做一些加工处理)
-使用@Around在切入点前后切入内容,并自己控制何时执行切入点自身的内容
-使用@AfterThrowing用来处理当切入内容部分抛出异常之后的处理逻辑
例如:
@Aspect
@Component
public class WebLogAspect {
//声明Logger对象
private Logger logger = Logger.getLogger(getClass());
//通过@Pointcut定义的切入点为com.didispace.web包下的所有函数
//(对web层所有请求处理做切入点)
//public *(表示对访问限定符也可以规定)com.didispace.web(web包下)..*.*(..)所有方法,而且参数随意
//声明一个切入点,webLog为切入点名称
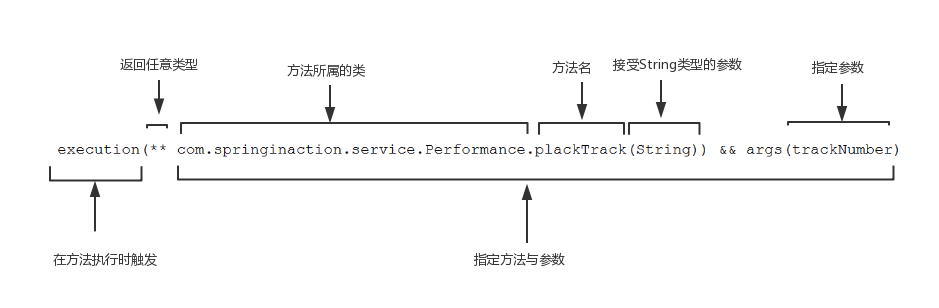
@Pointcut("execution(public * com.didispace.controller..*.*(..))")
public void webLog(){}
//用来具体实现webLog()方法
//JoinPoint对象封装了SpringAop中切面方法的信息,在切面方法中添加JoinPoint参数,
//就可以获取到封装了该方法信息的JoinPoint对象.
//JoinPoint其实就具象化为这个切面类
@Before("webLog()")
public void doBefore(JoinPoint joinPoint) throws Throwable {
// 接收到请求,记录请求内容
ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
HttpServletRequest request = attributes.getRequest();
// 记录下请求内容
//获取URL
logger.info("URL : " + request.getRequestURL().toString());
//获取请求方式
logger.info("HTTP_METHOD : " + request.getMethod());
//获取请求IP
logger.info("IP : " + request.getRemoteAddr());
//Signature getSignature();方法
//获取封装了署名信息的对象,在该对象中可以获取到目标方法名,所属类的Class等信息
//哪个方法触发了就输出哪个方法的方法名
logger.info("CLASS_METHOD : " + joinPoint.getSignature().getDeclaringTypeName() + "." + joinPoint.getSignature().getName());
//Object[] getArgs();
//获取传入目标方法的参数对象,也就是请求参数值
logger.info("ARGS : " + Arrays.toString(joinPoint.getArgs()));
}
//在切入点return内容之后切入内容(可以用来对处理返回值做一些加工处理)
//一旦切点有ruturn函数,则触发这个切面
@AfterReturning(returning = "ret", pointcut = "webLog()")
public void doAfterReturning(Object ret) throws Throwable {
// 处理完请求,返回内容
logger.info("RESPONSE : " + ret);
}
//后置异常通知
//有异常则输出这个
@AfterThrowing("webLog()")
public void throwss(JoinPoint joinPoint){
logger.error("Exception : "+joinPoint.getTarget());
}
//后置最终通知,final增强,不管是抛出异常或者正常退出都会执行
//最后一定执行,属于final级别
@After("webLog()")
public void after(JoinPoint jp){
System.out.println("方法最后执行.....");
}
//环绕通知,环绕增强,相当于MethodInterceptor
//其实我们仅使用环绕通知就可以实现前置通知、后置通知、异常通知、最终通知等的效果。
//ProceedingJoinPoint继承JoinPoint子接口,它新增了两个用于执行连接点方法的方法:
//1.Object proceed()通过反射执行目标对象的连接点处的方法
//2.Object proceed(java.lang.Object[] args)通过反射执行目标对象连接点处的方法,不过使用新的参数替换原来的参数。
@Around("webLog()")
public Object arround(ProceedingJoinPoint pjp) {
System.out.println("方法环绕start.....");
try {
//proceed()方法输出的是切入点的方法名
Object o = pjp.proceed();
System.out.println("方法环绕proceed,结果是 :" + o);
return o;
} catch (Throwable e) {
e.printStackTrace();
return null;
}
}
}
第六步:配置相关日志输出配置
// LOG4J配置
log4j.rootLogger=INFO, stdout, file, errorfile
// 动态识别多环境下的日志级别
log4j.category.com.didispace=${logging.level.com.didispace}, didifile
log4j.logger.error=errorfile
// 控制台输出
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p %c{1}:%L - %m%n
// root日志输出
log4j.appender.file=org.apache.log4j.DailyRollingFileAppender
log4j.appender.file.file=logs/all.log
log4j.appender.file.DatePattern='.'yyyy-MM-dd
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p %c{1}:%L - %m%n
// error日志输出
log4j.appender.errorfile=org.apache.log4j.DailyRollingFileAppender
log4j.appender.errorfile.file=logs/error.log
log4j.appender.errorfile.DatePattern='.'yyyy-MM-dd
log4j.appender.errorfile.Threshold = ERROR
log4j.appender.errorfile.layout=org.apache.log4j.PatternLayout
log4j.appender.errorfile.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p %c{1}:%L - %m%n
// com.didispace下的日志输出
log4j.appender.didifile=org.apache.log4j.DailyRollingFileAppender
log4j.appender.didifile.file=logs/my.log
log4j.appender.didifile.DatePattern='.'yyyy-MM-dd
log4j.appender.didifile.layout=org.apache.log4j.PatternLayout
log4j.appender.didifile.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p %c{1}:%L ---- %m%n
这样就将aop的信息打印到文件中了,我们可以结合springboot+log4j,实现aop的日志记录功能切入到业务逻辑中
关于AOP优化问题
AOP切面中的同步问题,也就是有关于性能审计的相关功能,若是我们想记录某个组件运行的时间,我们应该如何设计?
传统方式是在WebLogAspect切面中,分别通过doBefore和doAfterReturning两个独立函数实现了切点头部和切点返回后执行的内容,若我们想统计请求的处理时间,就需要在doBefore处记录时间,并在doAfterReturning处通过当前时间与开始处记录的时间计算得到请求处理的消耗时间。
那么我们是否可以在WebLogAspect切面中定义一个成员变量来给doBefore和doAfterReturning一起访问呢?是否会有同步问题呢?
的确,直接在这里定义基本类型会有同步问题,所以我们可以引入ThreadLocal对象,像下面这样进行记录:
@Aspect
@Component
public class WebLogAspect {
private Logger logger = Logger.getLogger(getClass());
ThreadLocal<Long> startTime = new ThreadLocal<>();
@Pointcut("execution(public * com.didispace.web..*.*(..))")
public void webLog(){}
@Before("webLog()")
public void doBefore(JoinPoint joinPoint) throws Throwable {
startTime.set(System.currentTimeMillis());
// 省略日志记录内容
}
@AfterReturning(returning = "ret", pointcut = "webLog()")
public void doAfterReturning(Object ret) throws Throwable {
// 处理完请求,返回内容
logger.info("RESPONSE : " + ret);
logger.info("SPEND TIME : " + (System.currentTimeMillis() - startTime.get()));
}
}
还有AOP切面的优先级,我们也可以进行控制,若是我们的业务中存在很多的AOP组件,那么如何管理他们的优先级呢?
由于通过AOP实现,程序得到了很好的解耦,但是也会带来一些问题,比如:我们可能会对Web层做多个切面,校验用户,校验头信息等等,这个时候经常会碰到切面的处理顺序问题。
所以,我们需要定义每个切面的优先级,我们需要@Order(i)注解来标识切面的优先级。i的值越小,优先级越高。假设我们还有一个切面是CheckNameAspect用来校验name必须为didi,我们为其设置@Order(10),而上文中WebLogAspect设置为@Order(5),所以WebLogAspect有更高的优先级,这个时候执行顺序是这样的:
在@Before中优先执行@Order(5)的内容,再执行@Order(10)的内容
在@After和@AfterReturning中优先执行@Order(10)的内容,再执行@Order(5)的内容
所以我们可以这样子总结:
在切入点前的操作,按order的值由小到大执行
在切入点后的操作,按order的值由大到小执行
就是一种像洋葱一样的aop结构,order越小就越外层。。。
SpringBoot中的事务管理支持
事务管理的功能模块主要用于业务层,因为业务层要调用持久层组件,实际是对数据读写的多步操作的结合。多步读写操作意味着多步调用持久层,期间每一步的读写操作都不能够错,一旦错就需要全部回滚,之前的所有操作都无效。
事务的作用就是为了保证用户的每一个操作都是可靠的,事务中的每一步操作都必须成功执行,只要有发生异常就回退到事务开始未进行操作的状态。
事务管理是Spring框架中最为常用的功能之一,我们在使用Spring Boot开发应用时,大部分情况下也都需要使用事务。(业务层使用)
在SpringBoot中,持久层组件常用mybatis-spring-boot-starter(Mybatis),spring-boot-starter-jdbc(JDBC)或spring-boot-starter-data-jpa(spring-data-jpa,相当于Hibernate的增强版)这三个持久层技术框架。
当我们使用了spring-boot-starter-jdbc或spring-boot-starter-data-jpa依赖的时候,框架会自动默认分别注入DataSourceTransactionManager或JpaTransactionManager。所以我们不需要任何额外配置就可以用@Transactional注解进行事务的使用。
在相应的业务层加上@Transactional即可。
通常我们在测试的时候,会加上@Rollback来保证每一次测试的独立性,即测试完逻辑代码后直接进行回滚,避免数据污染。
这些只是事务管理的默认配置,在实际开发中会出现较大较为复杂的项目代码(几十万行的项目?)
多数据源下的事务管理,只需要只需要通过value属性指定配置的事务管理器名即可,比如上面的PrimaryConfig和SecondaryConfig中配置了transactionManagerRef属性值,我们只要去声明即可:
@Transactional(value=”transactionManagerPrimary”)
除了指定不同的事务管理器之后,还能对事务进行隔离级别和传播行为的控制,下面分别详细解释:
-隔离级别
隔离级别是指若干个并发的事务之间的隔离程度,与我们开发时候主要相关的场景包括:脏读取、重复读、幻读。
我们可以看org.springframework.transaction.annotation.Isolation枚举类中定义了五个表示隔离级别的值:
public enum Isolation {
DEFAULT(-1),
READ_UNCOMMITTED(1),
READ_COMMITTED(2),
REPEATABLE_READ(4),
SERIALIZABLE(8);
}
DEFAULT:这是默认值,表示使用底层数据库的默认隔离级别。对大部分数据库而言,通常这值就是:READ_COMMITTED。
READ_UNCOMMITTED:该隔离级别表示一个事务可以读取另一个事务修改但还没有提交的数据。该级别不能防止脏读和不可重复读,因此很少使用该隔离级别。
READ_COMMITTED:该隔离级别表示一个事务只能读取另一个事务已经提交的数据。该级别可以防止脏读,这也是大多数情况下的推荐值。
REPEATABLE_READ:该隔离级别表示一个事务在整个过程中可以多次重复执行某个查询,并且每次返回的记录都相同。即使在多次查询之间有新增的数据满足该查询,这些新增的记录也会被忽略。该级别可以防止脏读和不可重复读。
SERIALIZABLE:所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
指定方法:通过使用isolation属性设置,例如:
@Transactional(isolation = Isolation.DEFAULT)
数据库事务隔离级别– 脏读、幻读、不可重复读又是什么?
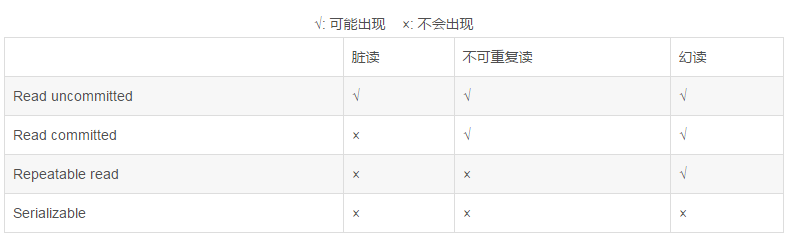
数据库事务的隔离级别有4个,由低到高依次为Read uncommitted 、Read committed 、Repeatable read 、Serializable ,这四个级别可以逐个解决脏读 、不可重复读 、幻读 这几类问题。(default表示committed)
脏读:公司发工资了,领导把5000元打到singo的账号上,但是该事务并未提交,而singo正好去查看账户,发现工资已经到账,是5000元整,非常高 兴。可是不幸的是,领导发现发给singo的工资金额不对,是2000元,于是迅速回滚了事务,修改金额后,将事务提交,最后singo实际的工资只有 2000元,singo空欢喜一场。
出现上述情况,即我们所说的脏读 ,两个并发的事务,“事务A:领导给singo发工资”、“事务B:singo查询工资账户”,事务B读取了事务A尚未提交的数据并以为这是已经存在的正确的数据(读到了脏东西),脏即指未提交数据。
当隔离级别设置为Read uncommitted 时,就可能出现脏读
定义:脏读就是指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。
不可重复读:singo拿着工资卡去消费,系统读取到卡里确实有2000元,而此时她的老婆也正好在网上转账,把singo工资卡的2000元转到另一账户,并在 singo之前提交了事务,当singo扣款时,系统检查到singo的工资卡已经没有钱,扣款失败,singo十分纳闷,明明卡里有钱,为 何……
出现上述情况,即我们所说的不可重复读 ,两个并发的事务,“事务A:singo消费”、“事务B:singo的老婆网上转账”,事务A事先读取了数据,事务B紧接了更新了数据,并提交了事务,而事务A再次读取该数据时,数据已经发生了改变。
当隔离级别设置为Read committed 时,避免了脏读,但是可能会造成不可重复读。
大多数数据库的默认级别就是Read committed,比如Sql Server , Oracle。
当隔离级别设置为Repeatable read 时,可以避免不可重复读。当singo拿着工资卡去消费时,一旦系统开始读取工资卡信息(即事务开始),singo的老婆就不可能对该记录进行修改,也就是singo的老婆不能在此时转账。
定义:是指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。(即不能读到相同的数据内容)
例如,一个编辑人员两次读取同一文档,但在两次读取之间,作者重写了该文档。当编辑人员第二次读取文档时,文档已更改。原始读取不可重复。如果只有在作者全部完成编写后编辑人员才可以读取文档,则可以避免该问题。
幻读:singo的老婆工作在银行部门,她时常通过银行内部系统查看singo的信用卡消费记录。有一天,她正在查询到singo当月信用卡的总消费金额 (select sum(amount) from transaction where month = 本月)为80元,而singo此时正好在外面胡吃海塞后在收银台买单,消费1000元,即新增了一条1000元的消费记录(insert transaction … ),并提交了事务,随后singo的老婆将singo当月信用卡消费的明细打印到A4纸上,却发现消费总额为1080元,singo的老婆很诧异,以为出 现了幻觉,幻读就这样产生了。
Mysql的默认隔离级别就是Repeatable read。
定义:是指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象发生了幻觉一样。
例如,一个编辑人员更改作者提交的文档,但当生产部门将其更改内容合并到该文档的主复本时,发现作者已将未编辑的新材料添加到该文档中。如果在编辑人员和生产部门完成对原始文档的处理之前,任何人都不能将新材料添加到文档中,则可以避免该问题。
我们讨论隔离级别的场景,主要是在多个事务并发 的情况下,因此,接下来的讲解都围绕事务并发。
Serializable 序列化(最强的隔离级别,序列化,但是及其损耗资源)
Serializable 是最高的事务隔离级别,同时代价也花费最高,性能很低,一般很少使用,在该级别下,事务顺序执行,不仅可以避免脏读、不可重复读,还避免了幻像读。
-传播行为
所谓事务的传播行为是指,如果在开始当前事务之前,一个事务上下文已经存在,此时有若干选项可以指定一个事务性方法的执行行为。
我们可以看org.springframework.transaction.annotation.Propagation枚举类中定义了6个表示传播行为的枚举值:
public enum Propagation {
REQUIRED(0),
SUPPORTS(1),
MANDATORY(2),
REQUIRES_NEW(3),
NOT_SUPPORTED(4),
NEVER(5),
NESTED(6);
}
REQUIRED:如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
MANDATORY:如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
REQUIRES_NEW:创建一个新的事务,如果当前存在事务,则把当前事务挂起。
NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,则把当前事务挂起。
NEVER:以非事务方式运行,如果当前存在事务,则抛出异常。
NESTED:如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于REQUIRED。
指定方法:通过使用propagation属性设置,例如:
@Transactional(propagation = Propagation.REQUIRED)
如何学习Spring Boot:https://www.zhihu.com/question/53729800/answer/255785661

